Assignment
Library
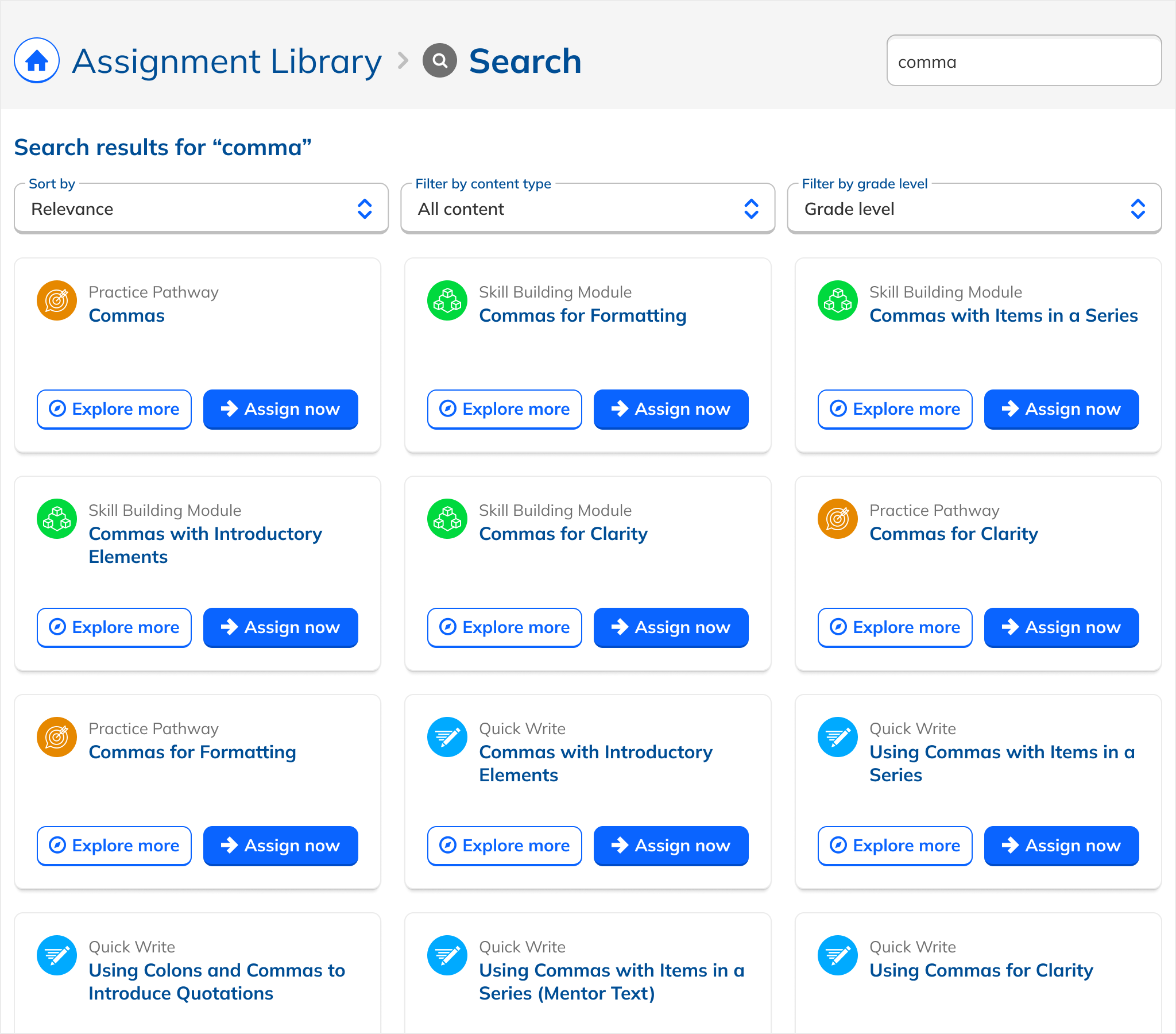
Search.
How rebuilding search from the ground up surfaced writing content, shifted teacher behavior, and drove a 23% increase in adoption.
Ben Dansby · Product Design
Four layers of improvement.
Fixing Search wasn't a UI problem alone. Working with a PM, curriculum specialist, and engineer, we tackled it across four layers, each one unlocking the next.
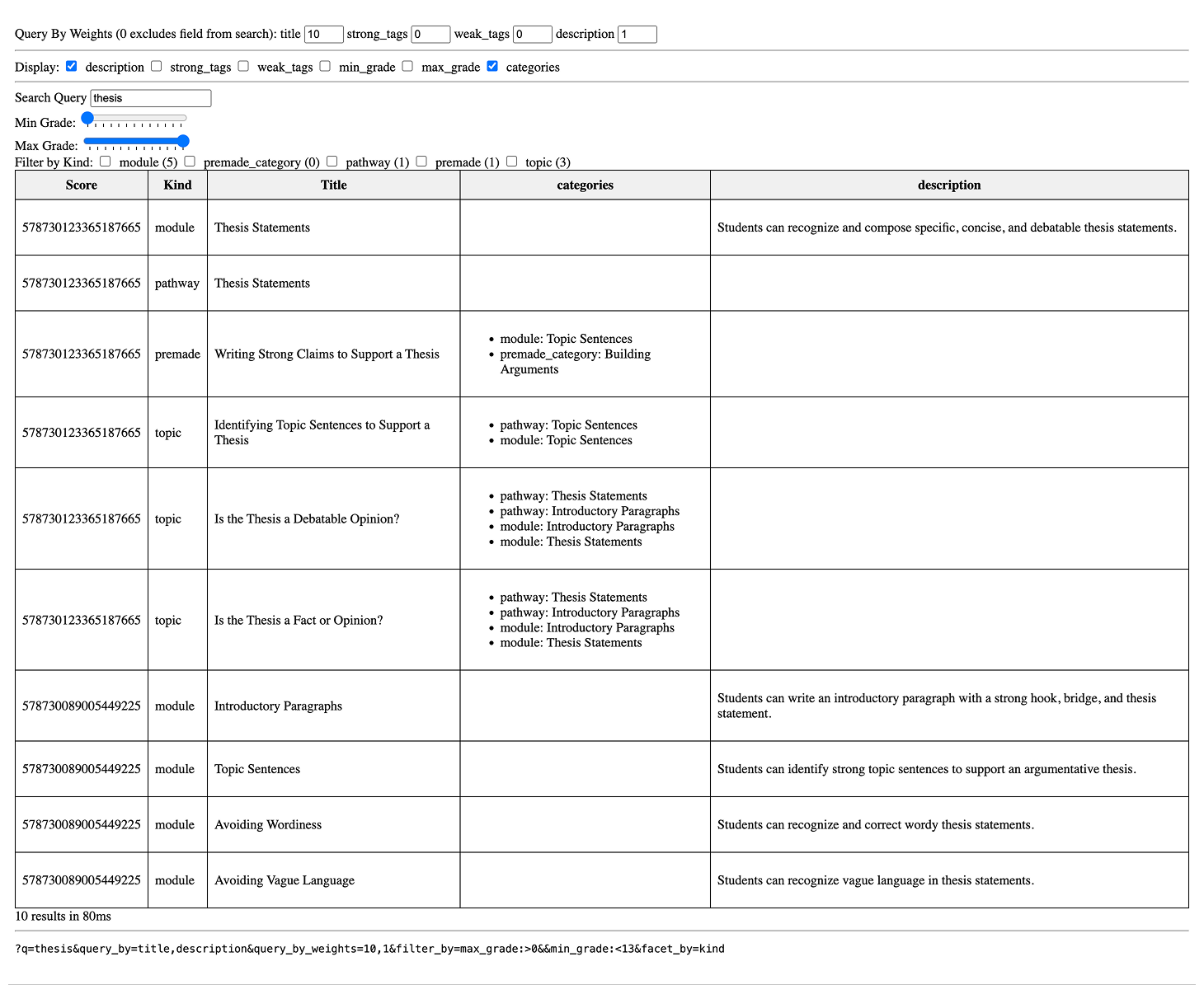
Backend migration
Moved from a slow frontend-based system to a backend search engine. Eliminated performance issues, enabled full-library indexing, and unlocked relevance tuning.
Tiered weighting framework
High-leverage writing modules received additional weight. Synonym groups and manual overrides honored teacher intent. Exact matches always outranked fuzzy ones.
Full writing prompt indexing
For the first time, individual writing prompts were indexed and returned as results, opening vast new swathes of writing content to search users.
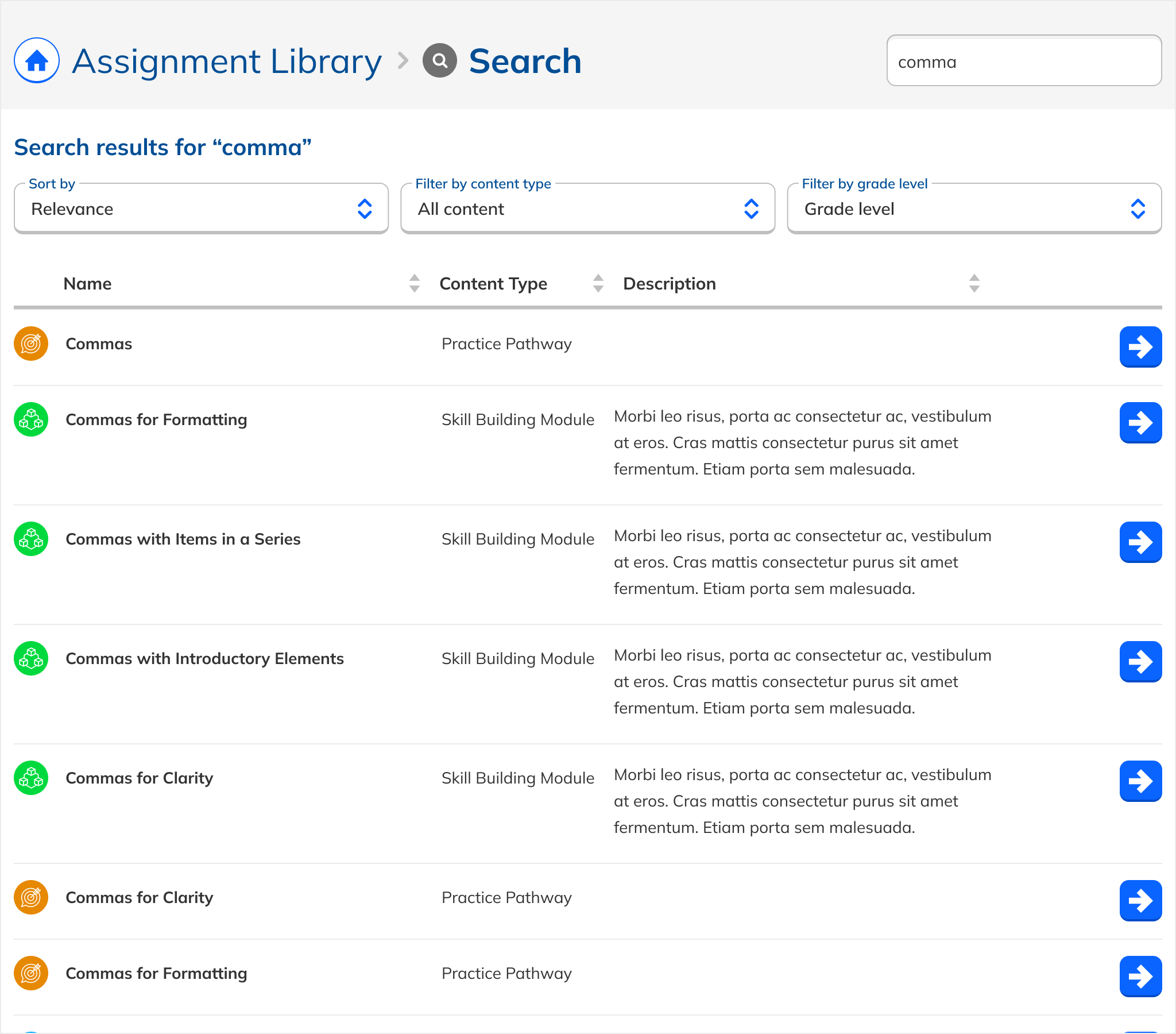
Redesigned UI
A simple, clearly labeled, filterable results list. Low learning curve, uniform formatting, single consistent action per result.
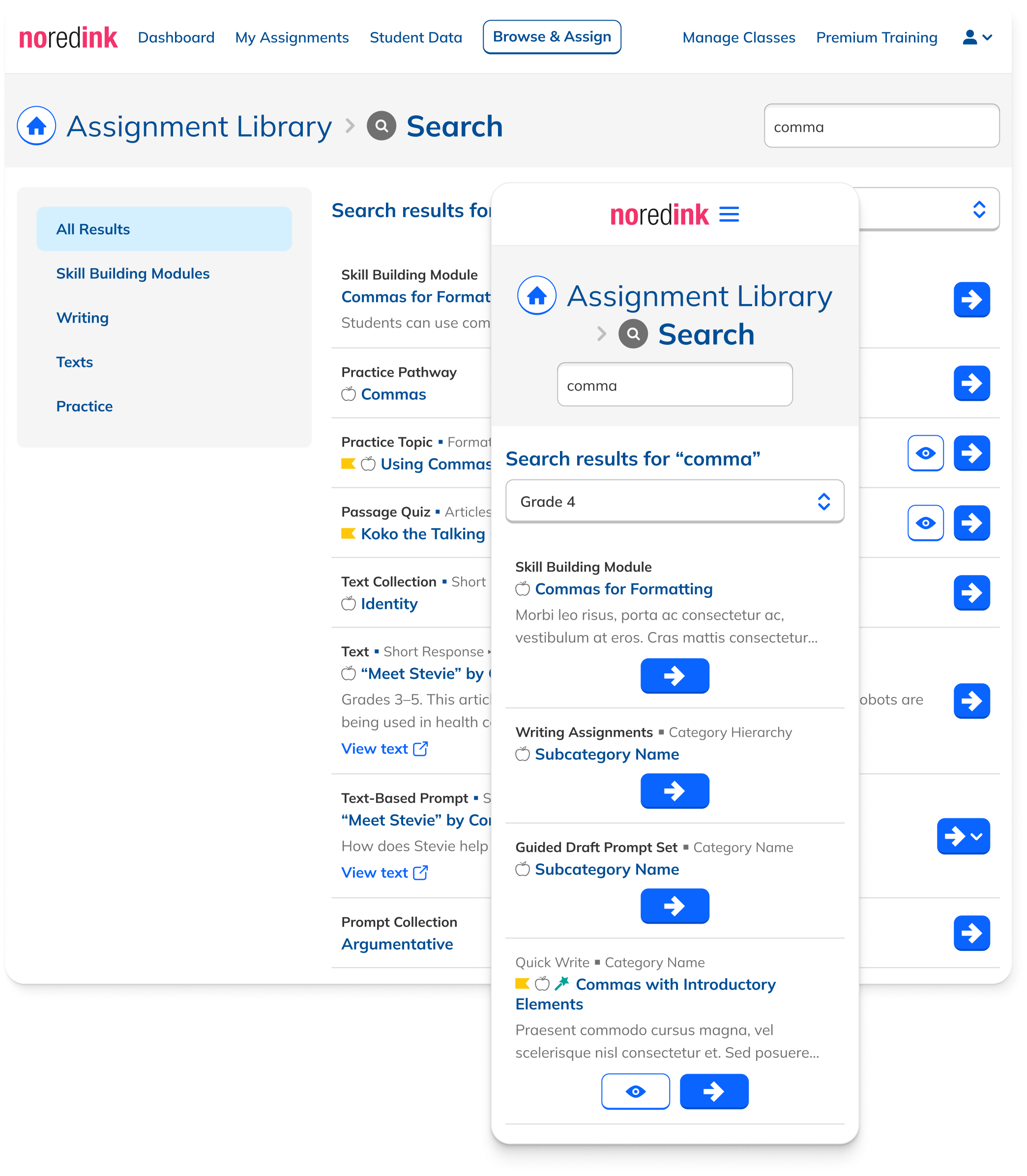
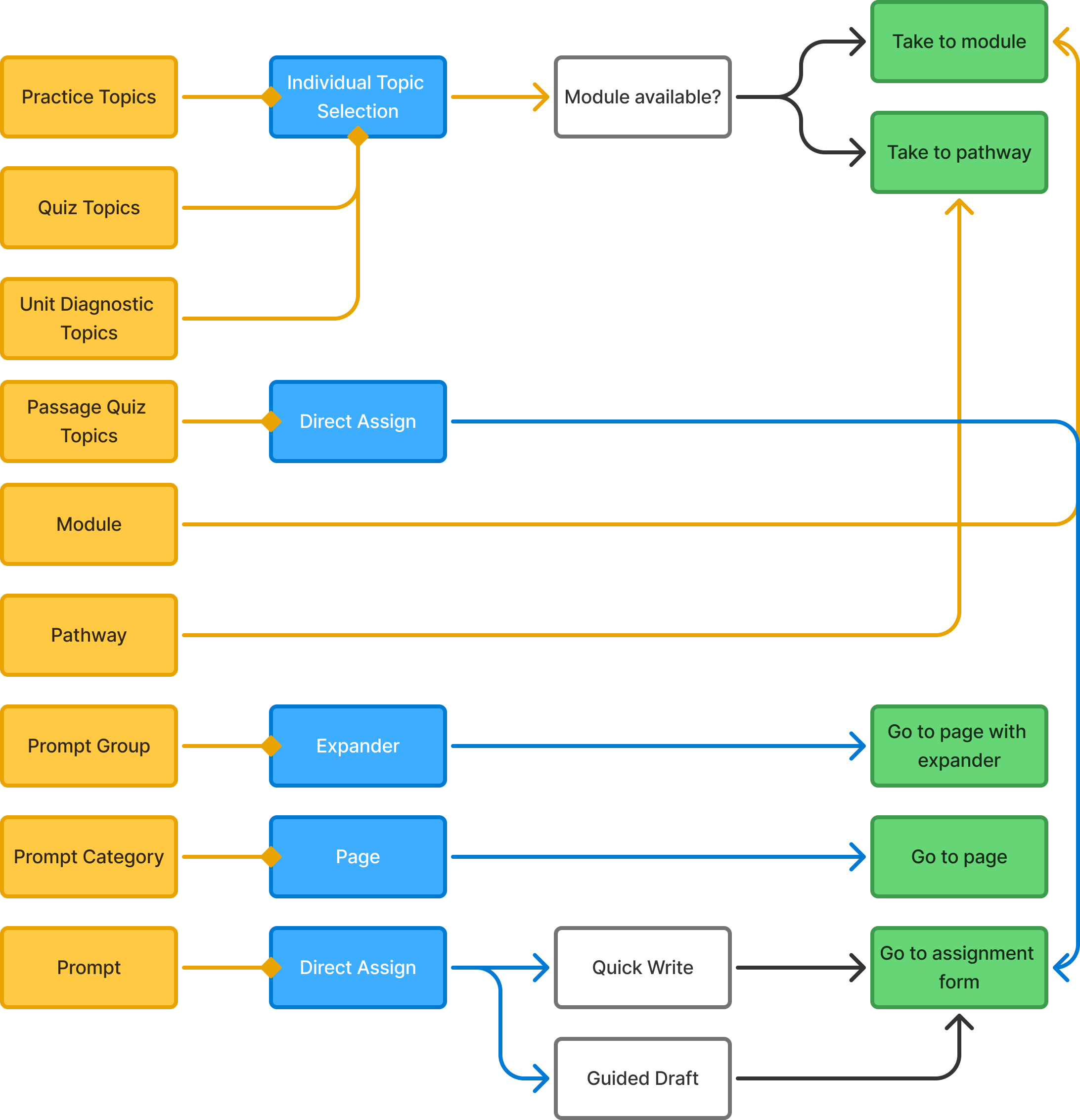
Heterogeneous content, unified experience.
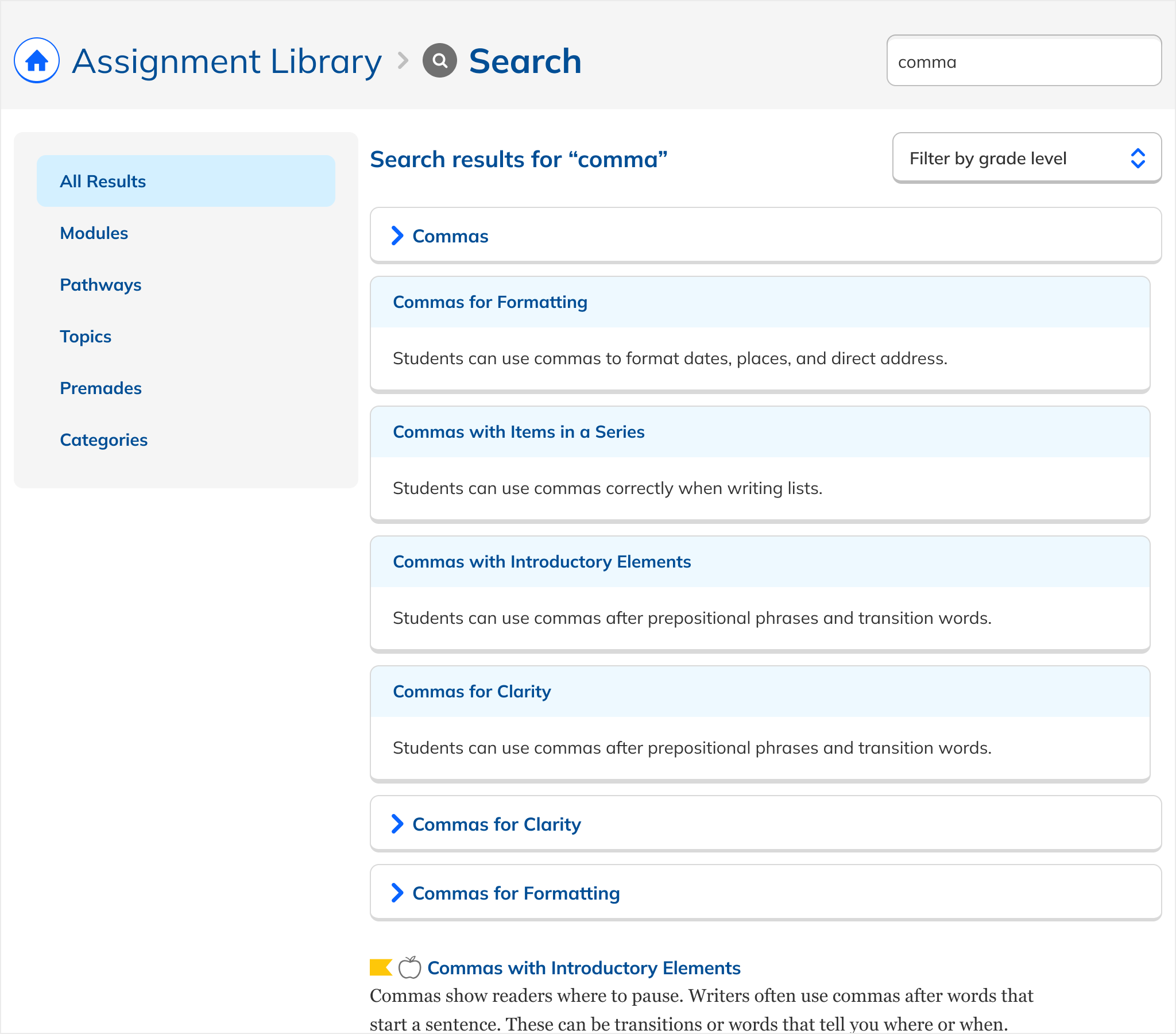
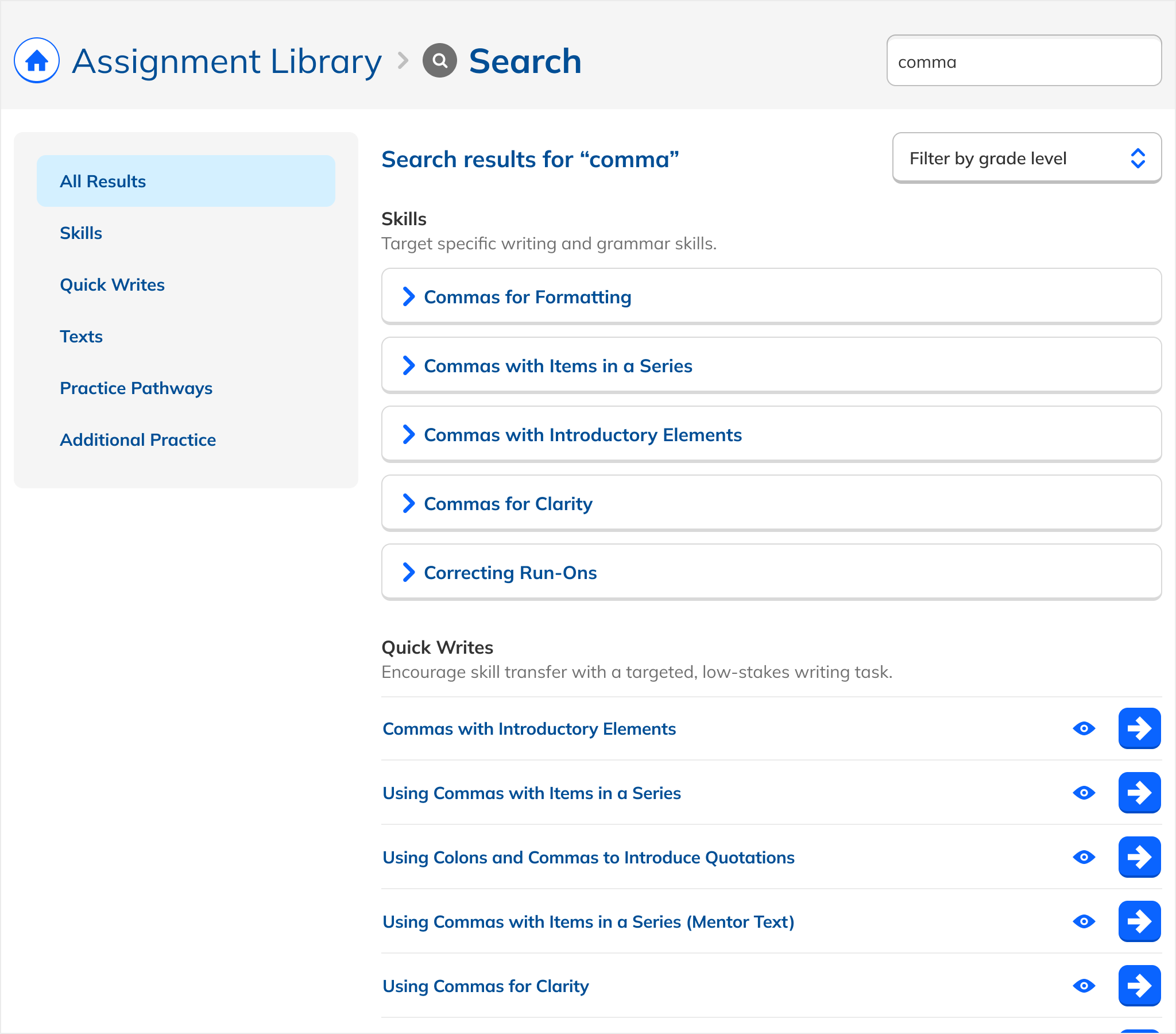
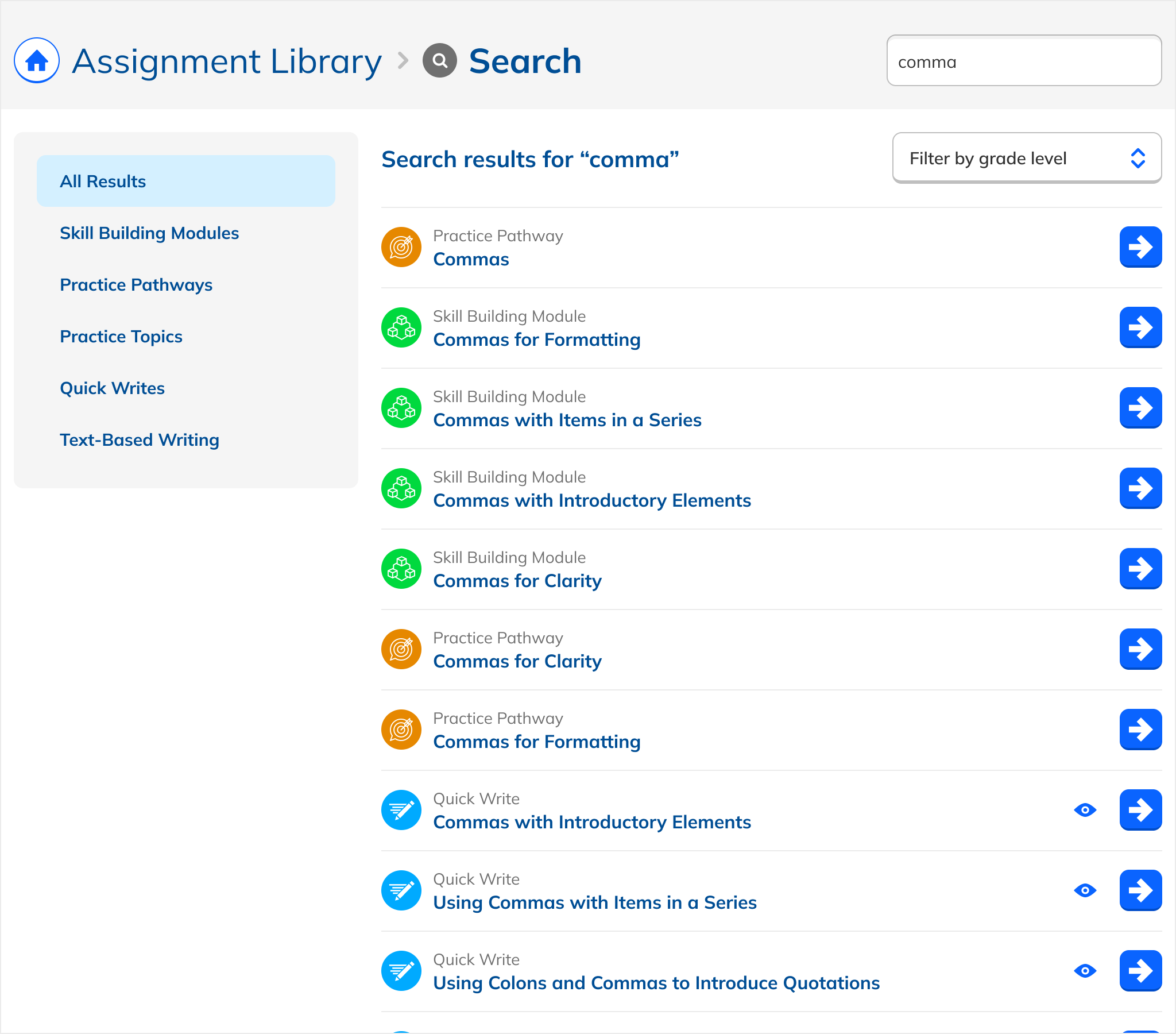
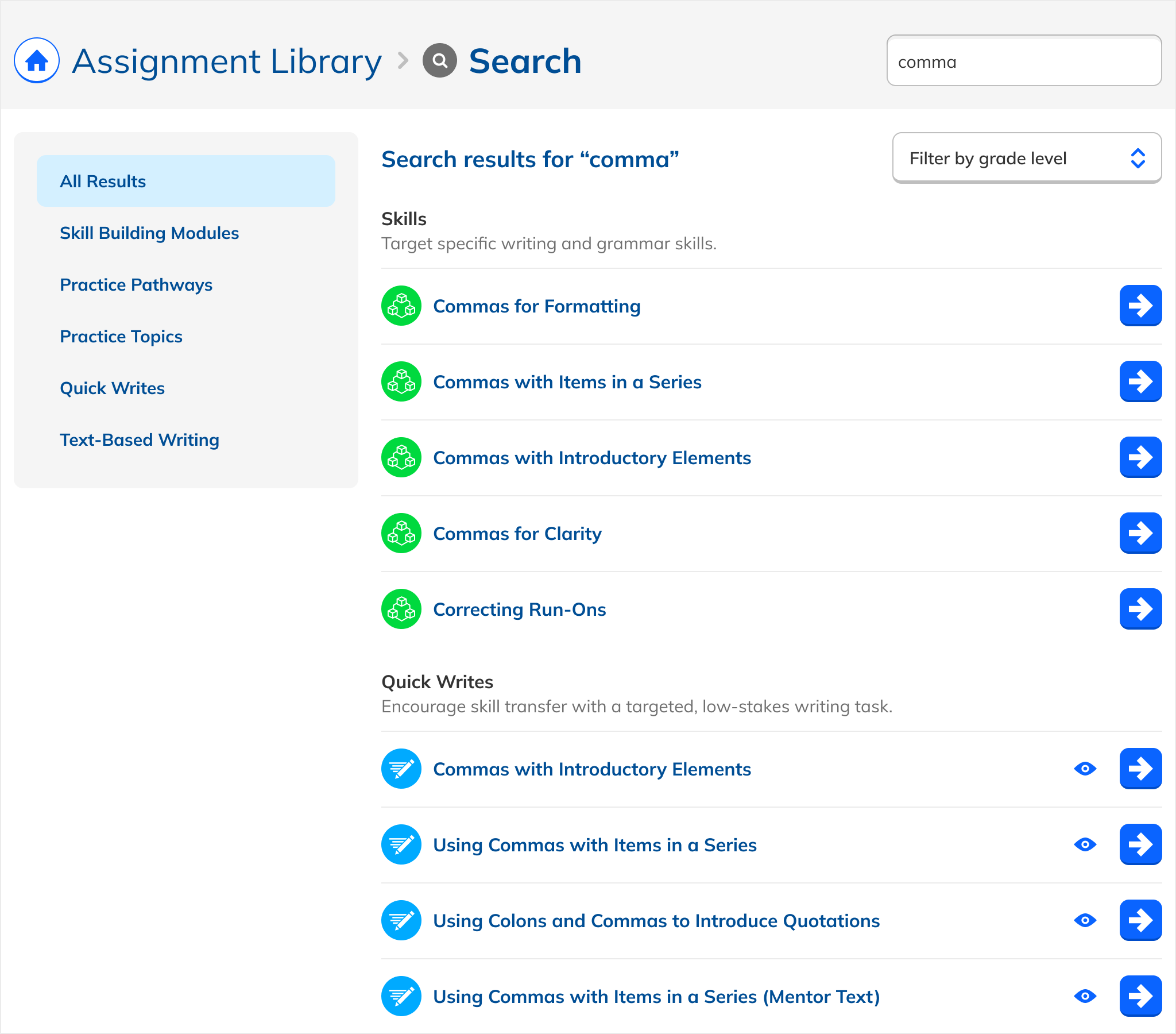
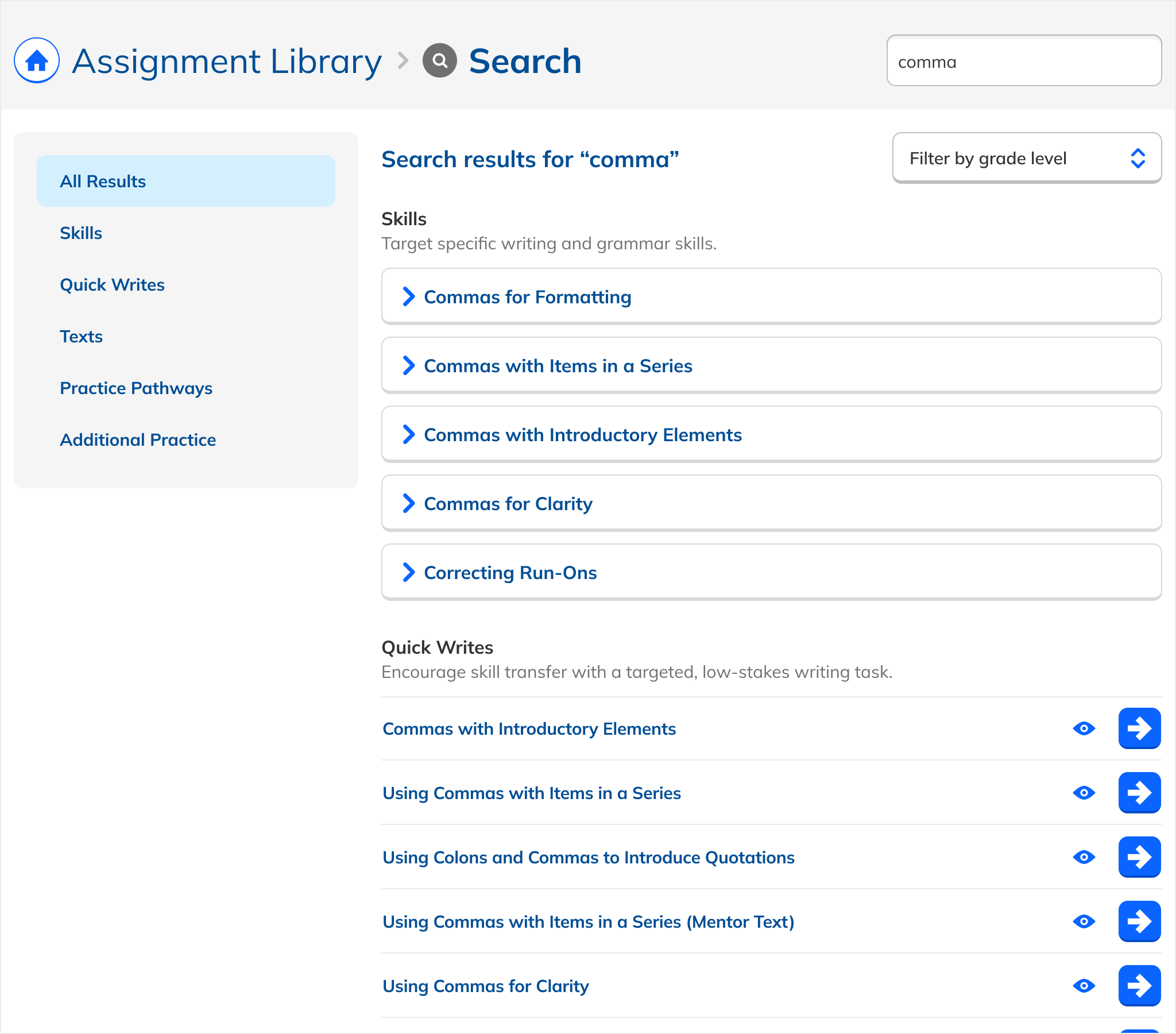
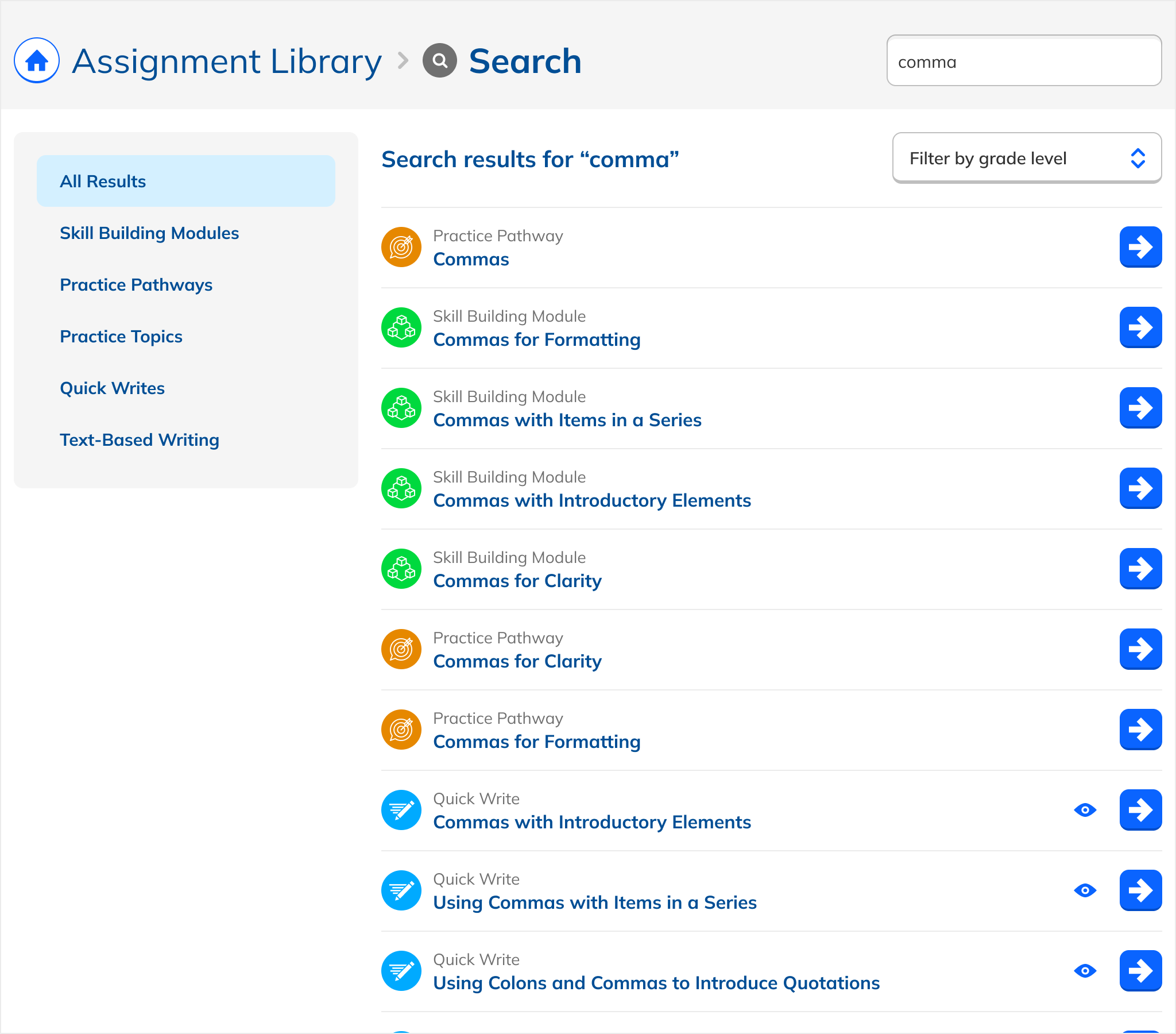
A major design challenge: the Assignment Library contains fundamentally different types of content with different behaviors. Practice Topics are checkboxes combined into assignments. Writing Prompts are standalone flows. Passage Quizzes can only be assigned as Quizzes. Modules and Pathways group related content.
Early iterations reflected this native variety: each type looked and functioned as it did in the library. But this created cognitive load: users had to learn multiple interaction patterns just to act on search results.
The solution: uniform presentation across all types. Every result appeared in the same format, with a single action that took the user to a dedicated page. The emphasis shifted from content logistics to content itself.
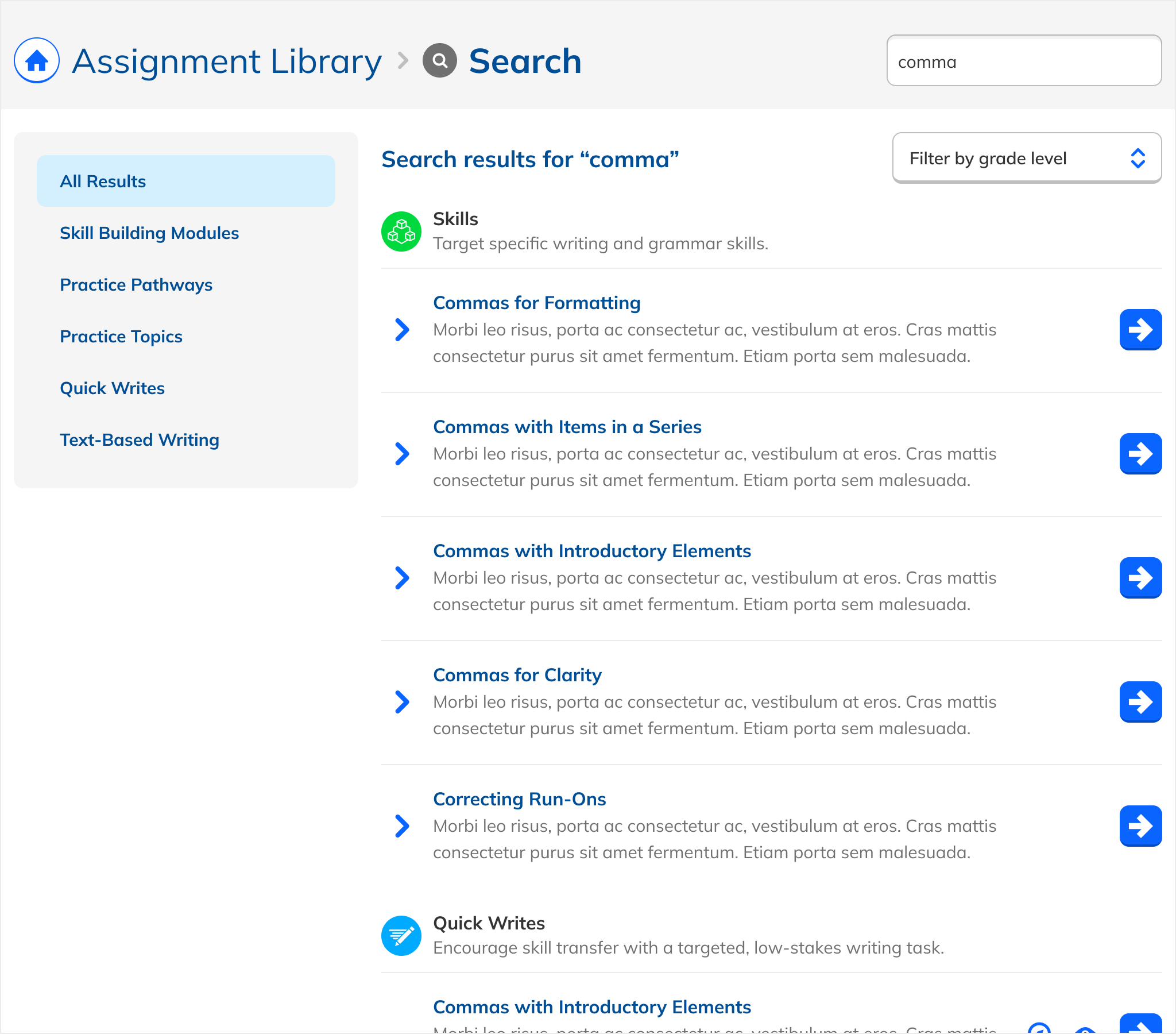
Nearly 30 iterations.
The design evolved in tight coupling with a live prototype, as relevance weights and tags were adjusted in parallel. Early iterations tried iconography, grouped sections, grid layouts, and varying amounts of metadata. Each path eventually led back to the same insight: the simpler, the better.