Based on what we were hearing from teachers, we established some design principles to guide our outcome:
- Teacher-first: Teachers must always remain in control of grading decisions.
- Transparent: Show how the AI reached its judgment.
- Lightweight: Reduce grading effort rather than introducing new workflows.
- Aligned: Follow familiar rubric structures grounded in curriculum accuracy.
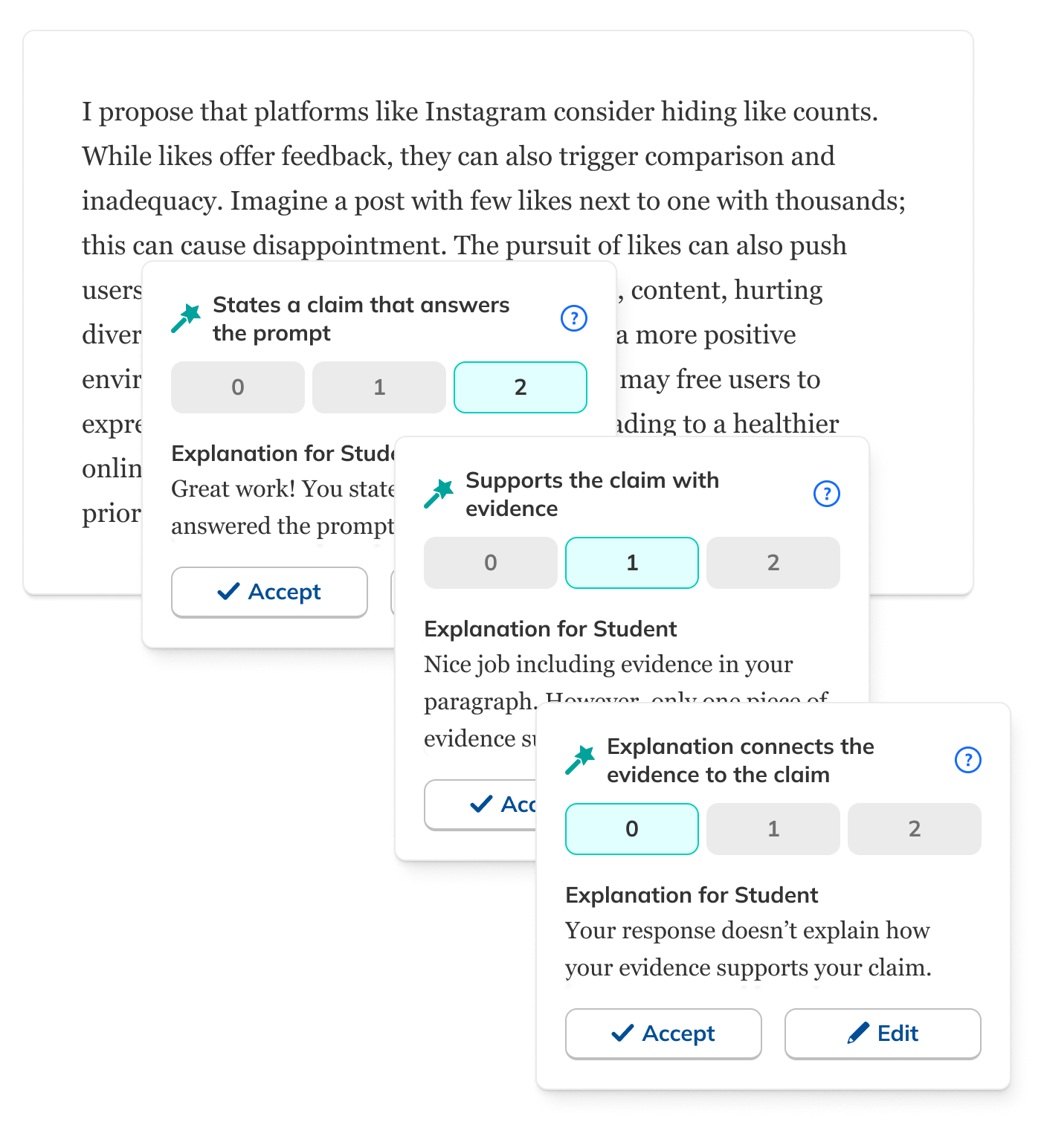
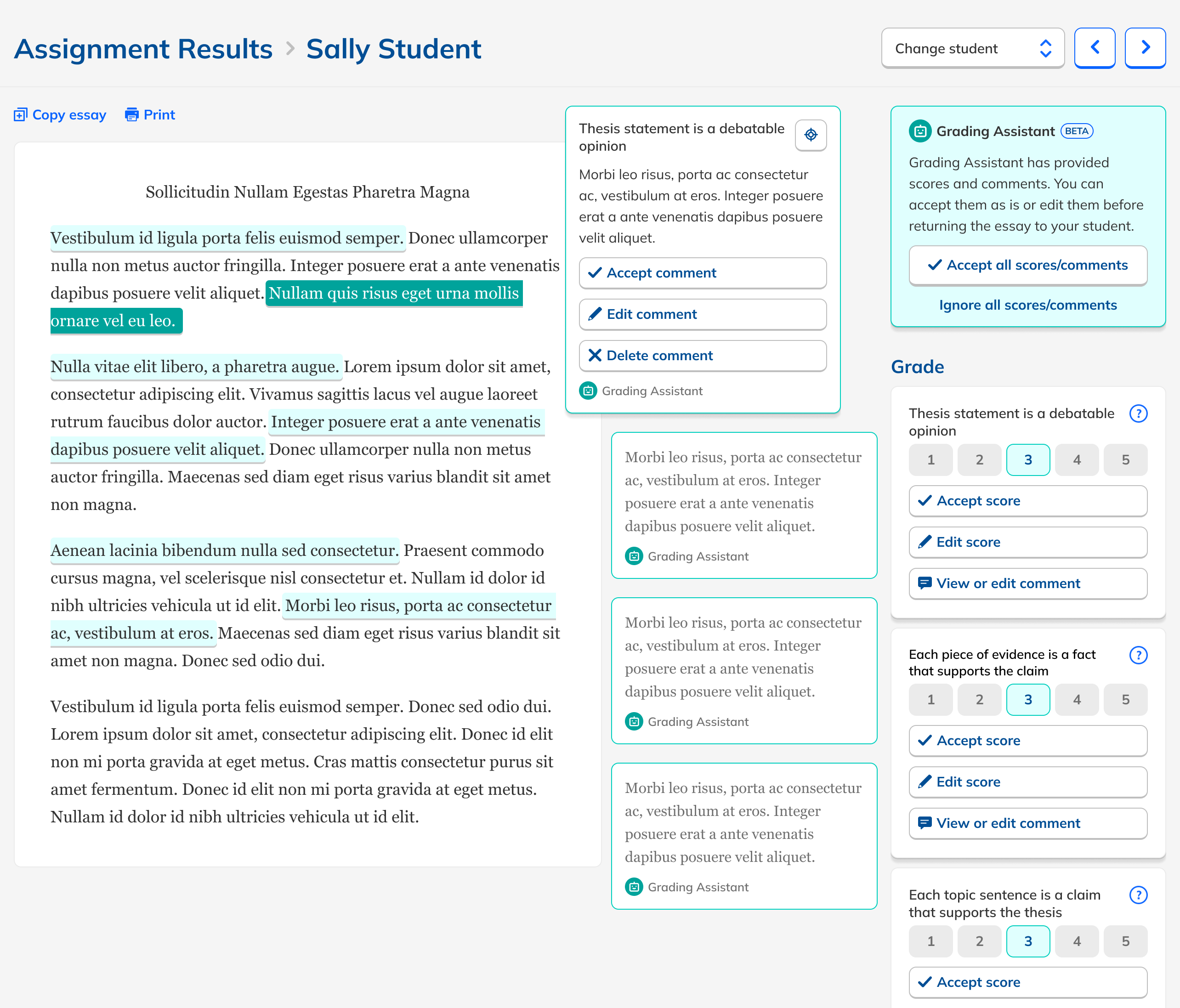
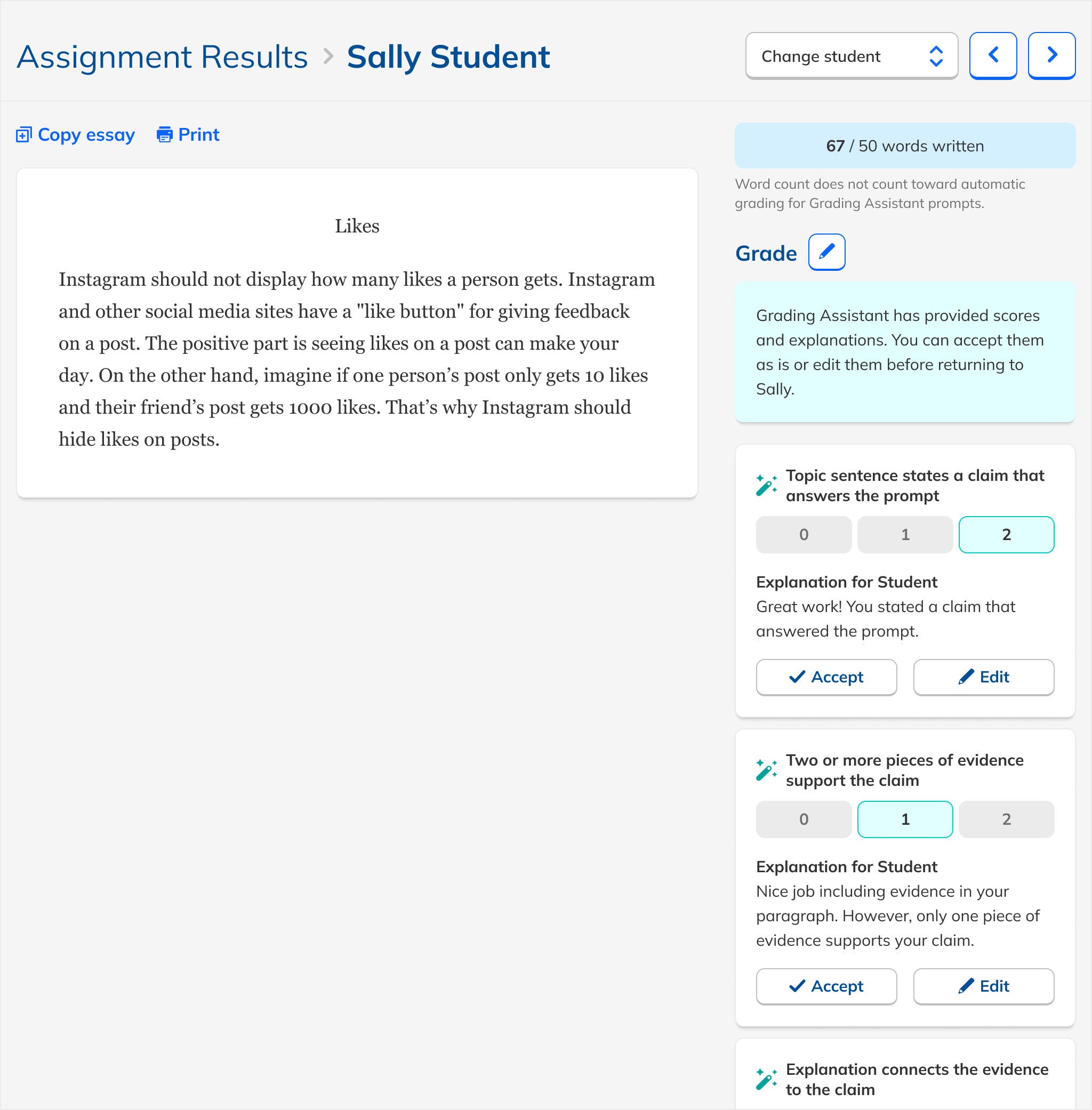
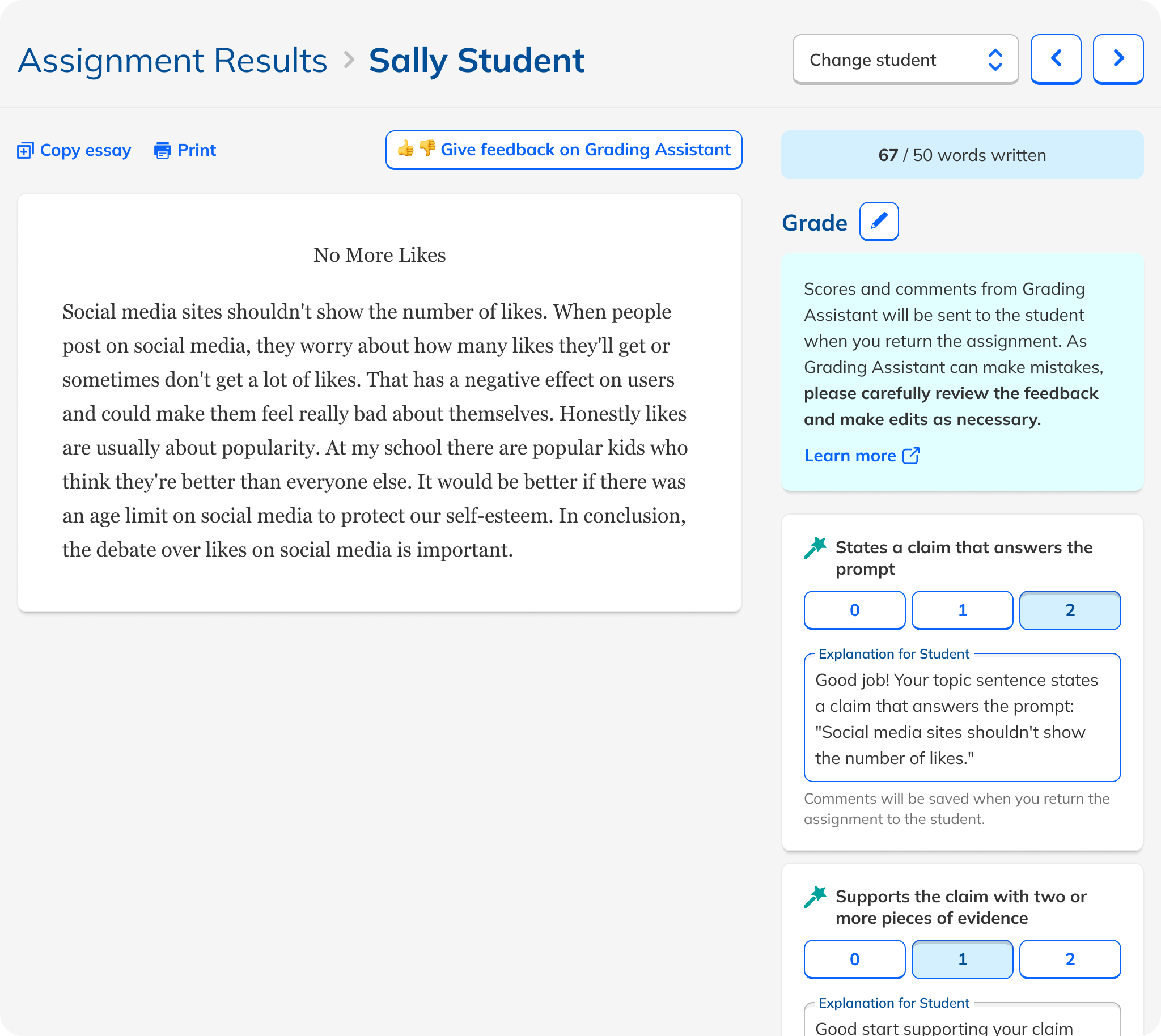
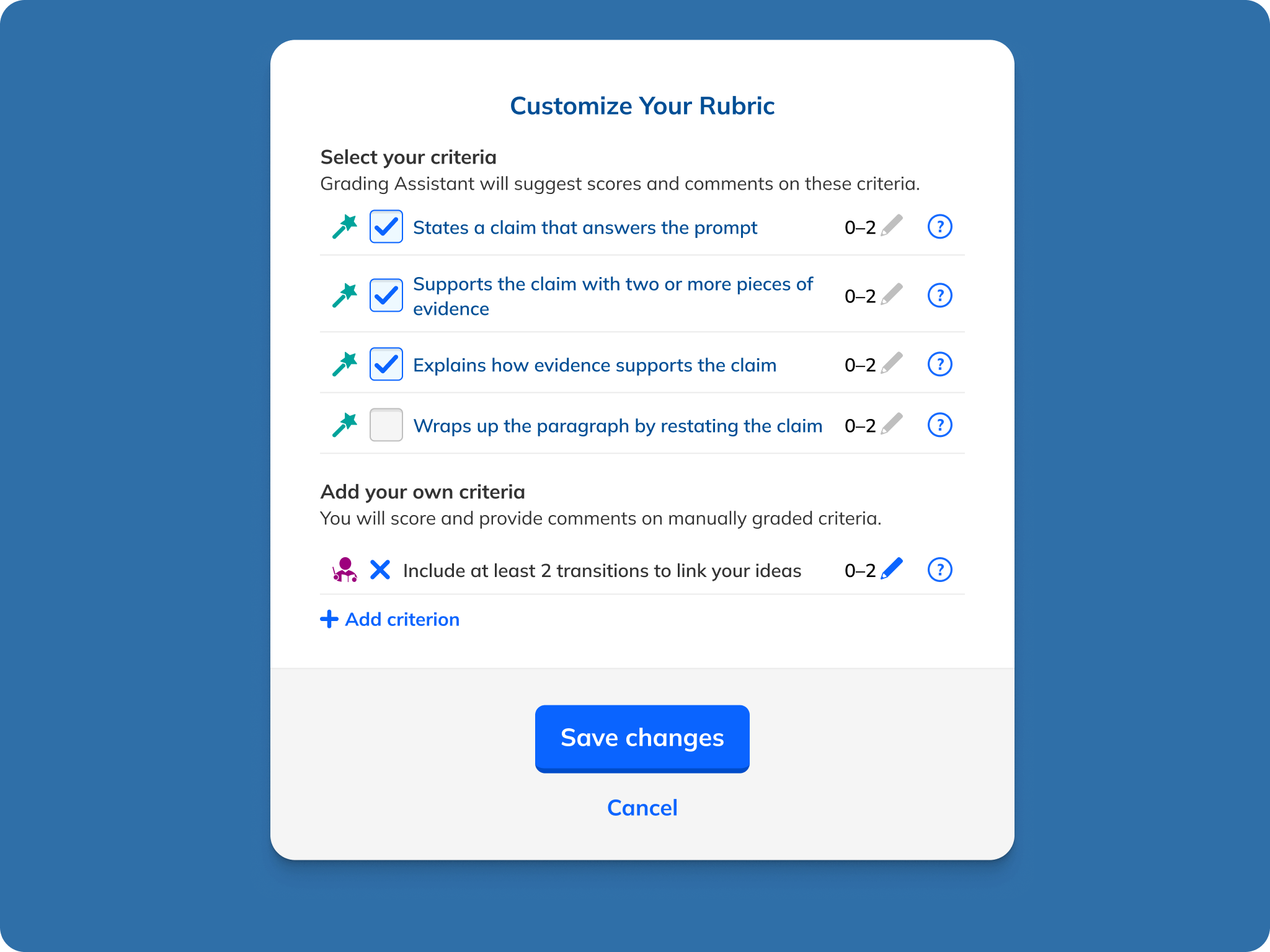
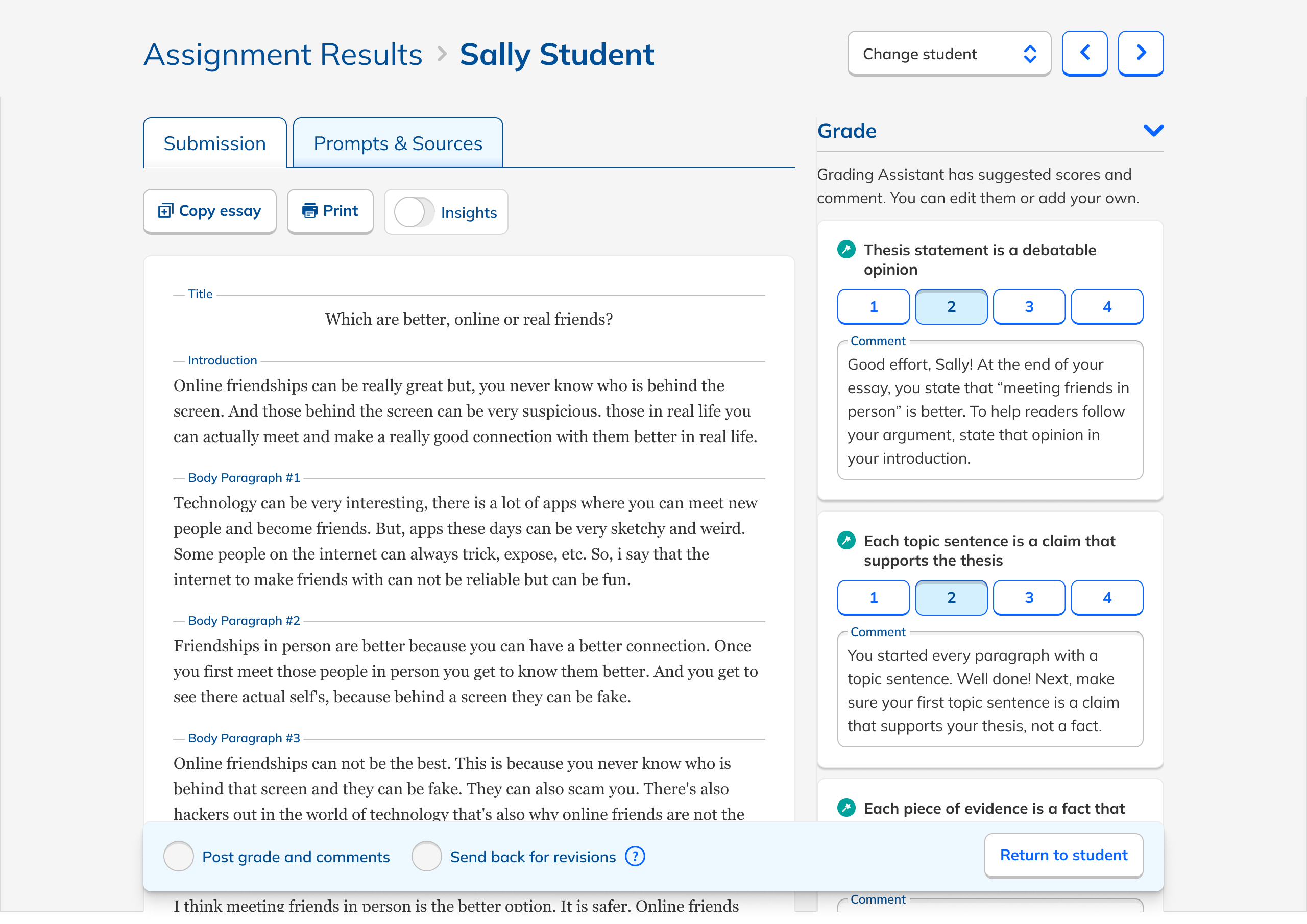
These principles led me to a design that used the existing rubric-based grading interface as a starting point. This followed the principles of lightness and alignment. I then added AI feedback as comments for the student, which doubled as explanations for the teacher. This is both lightweight and transparent, another principle. I designed the experience so that teachers needed either to edit or approve the AI feedback, supporting our teacher-first principle.
I started with an expansive prototype that included both in-line commenting and general comments. This helped sell the concept to our leadership team and provided us a canvas to test ideas on. I also tested alternate grading setups with test teachers, including a general rubric that used growth icons versus numbers, a checklist-based assessment, and comments not tied to a rubric. This verified that teachers preferred an automated grading system tightly coupled to a structured rubric, which our experiments with LLMs had revealed performed best at, a happy confluence. I also ended up dropping in-line and general commenting to keep scope in check.
One particular area of focus of my design process was how explicitly teachers should need to review/approve the AI feedback. Initially, my design included both conveniences and safeguards. Teachers were asked to approve individual comments, but they could also mass approve them. Teachers could skip approval, but a nag modal encouraged them to give things another lookover. Ultimately, out of a desire to ensure that students received only feedback that had been vetted by their teachers and not an unaccountable AI, I removed the ability for teachers to mass approve all feedback. It was early days in teachers' and students' relationships with AI, and maintaining trust was paramount. But conversely, to avoid having the experience become too onerous, I removed the nag modal.