Grading
Assistant.
How we designed an AI grading tool that cut teacher grading time in half and tripled student access to written feedback.
Ben Dansby · Product Design
Layer in, don't replace.
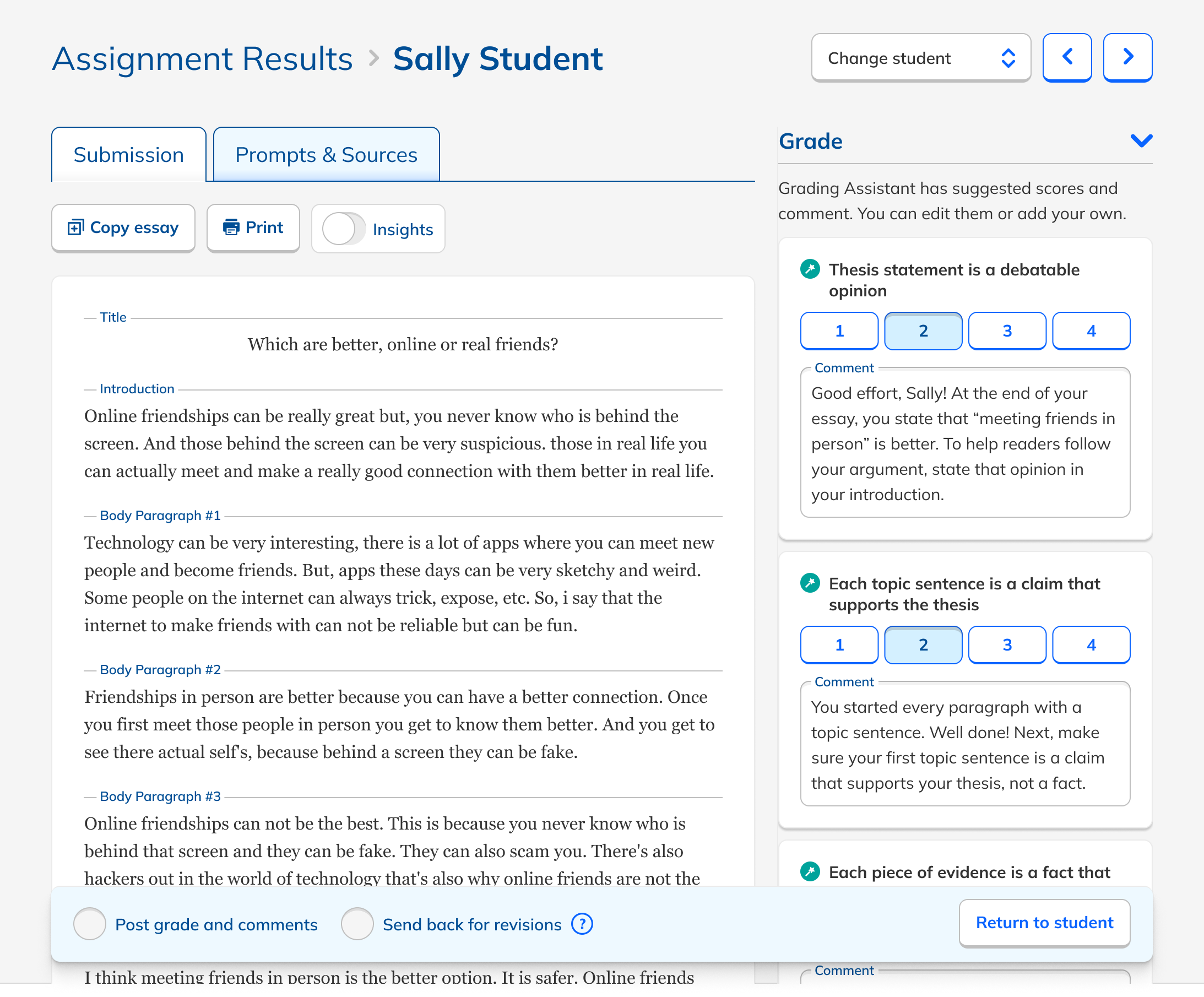
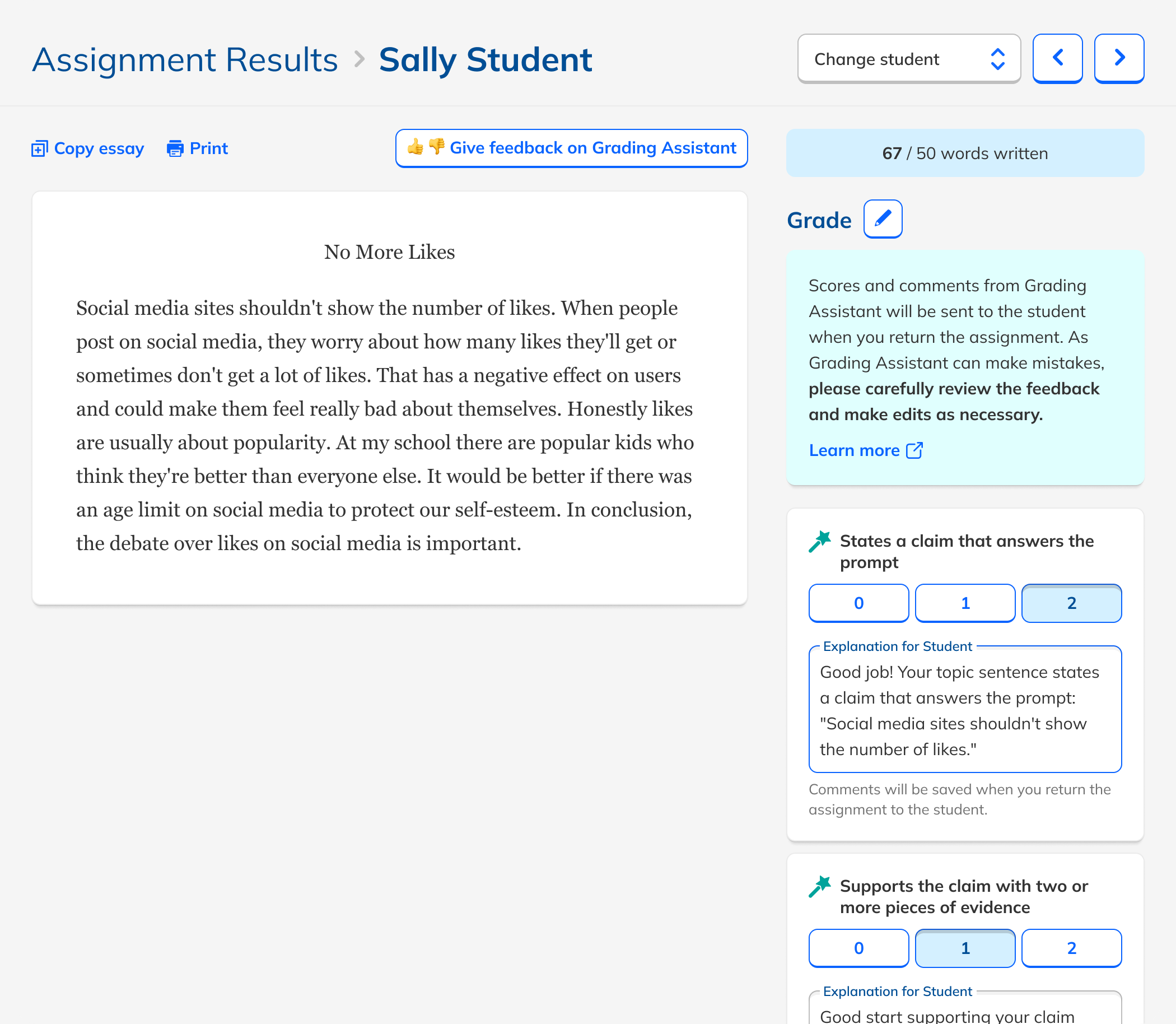
Rather than reinventing the grading workflow, I added AI feedback directly into NoRedInk's existing rubric-based grading interface.
AI comments appeared as suggested feedback for students, which also served as explanations for the teacher. Transparent by design.
Teachers had to edit or approve each comment, keeping them clearly responsible for the final grade.
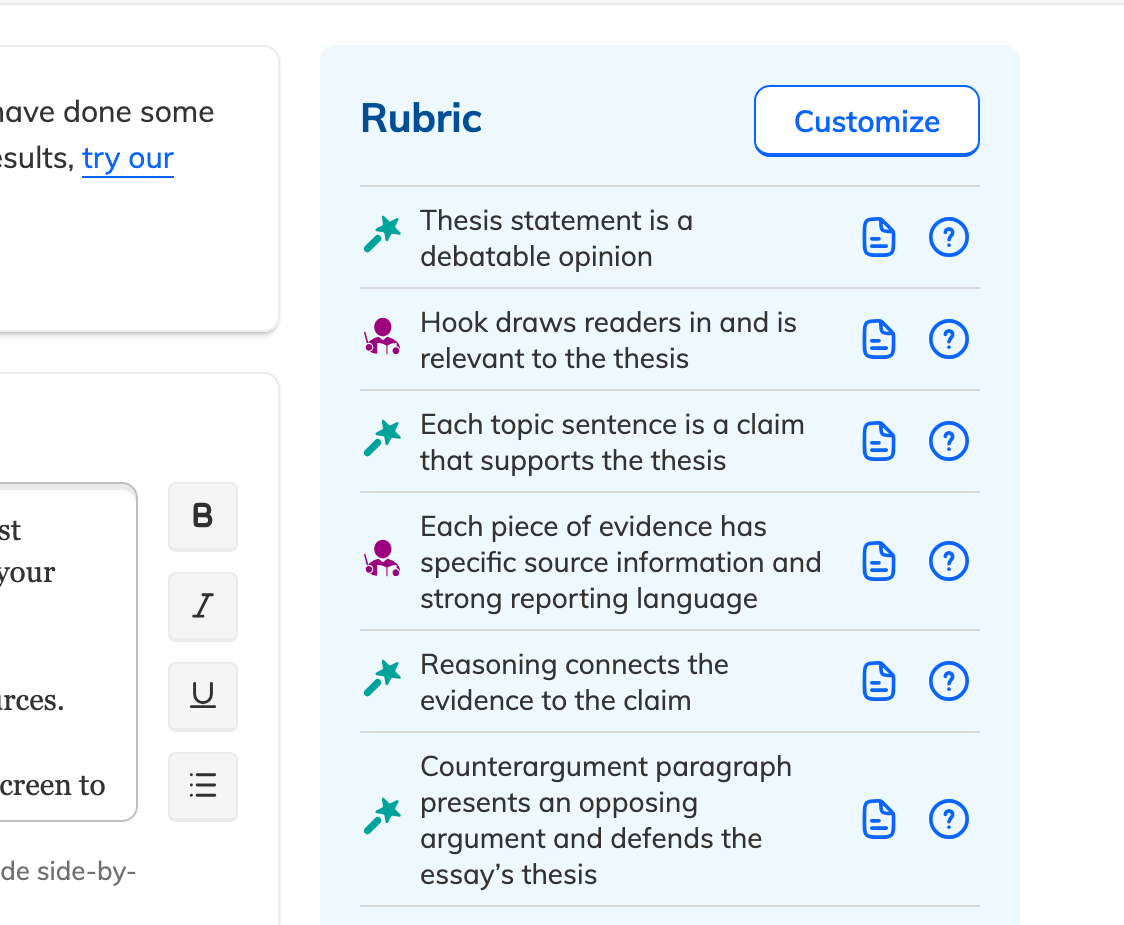
We tested inline comments, general comments, different rubric styles, checklist grading, and non-rubric feedback. Teachers consistently preferred rubric-tied feedback, which also happened to be where the LLM performed best.
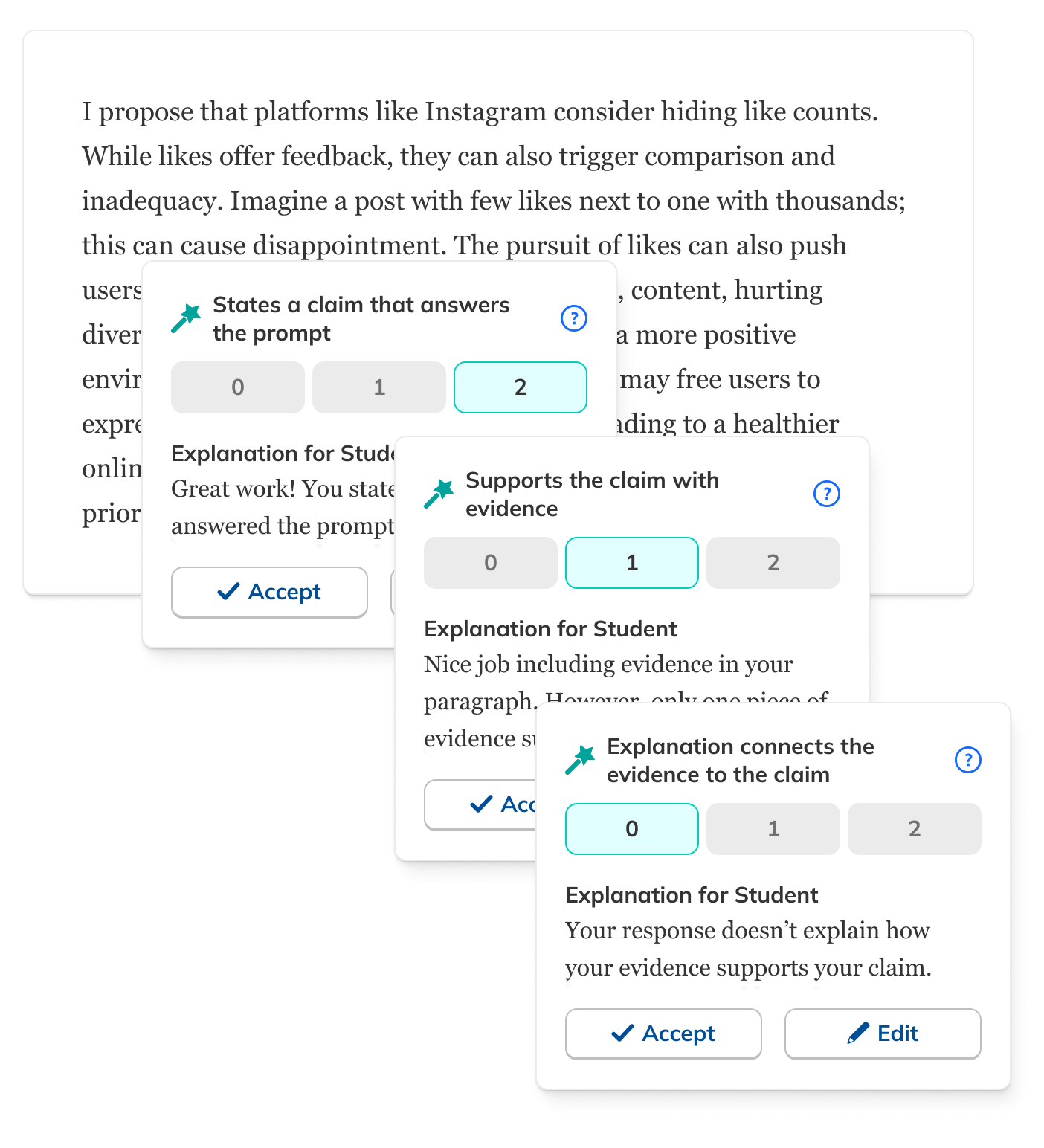
How much should teachers have to review?
One of the trickiest design questions: how explicit should the review step be? Too little and teachers felt unaccountable. Too much and it defeated the purpose.
Mass approve all
Removed. Felt irresponsible at a time when trust in AI was still fragile. Students deserve vetted feedback.
Nag modal for skipped reviews
Removed. Added friction without meaningfully improving trust or outcomes.
Approve comments individually
The right balance: explicit teacher review without overwhelming the workflow.
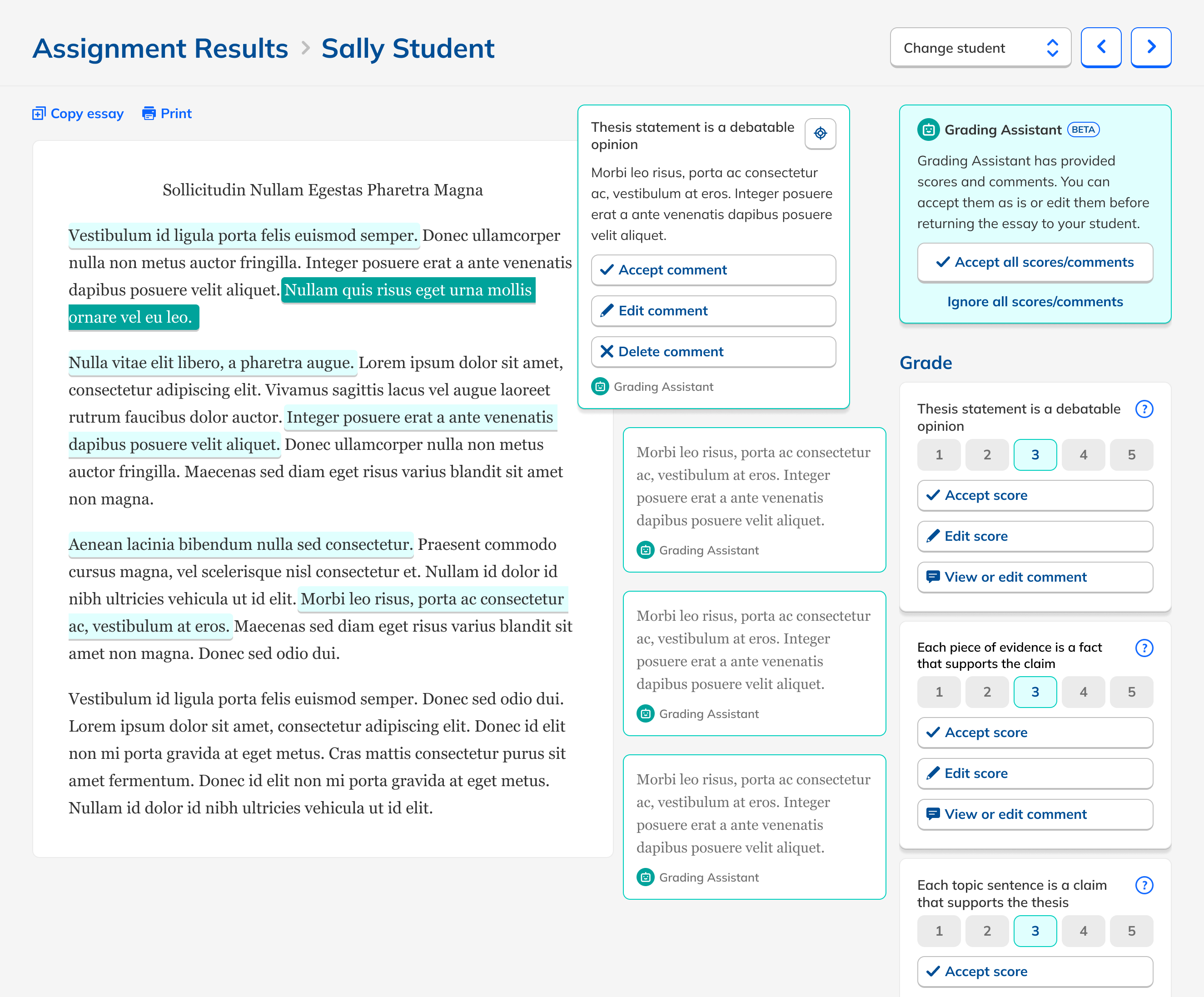
Simplify, then simplify again.
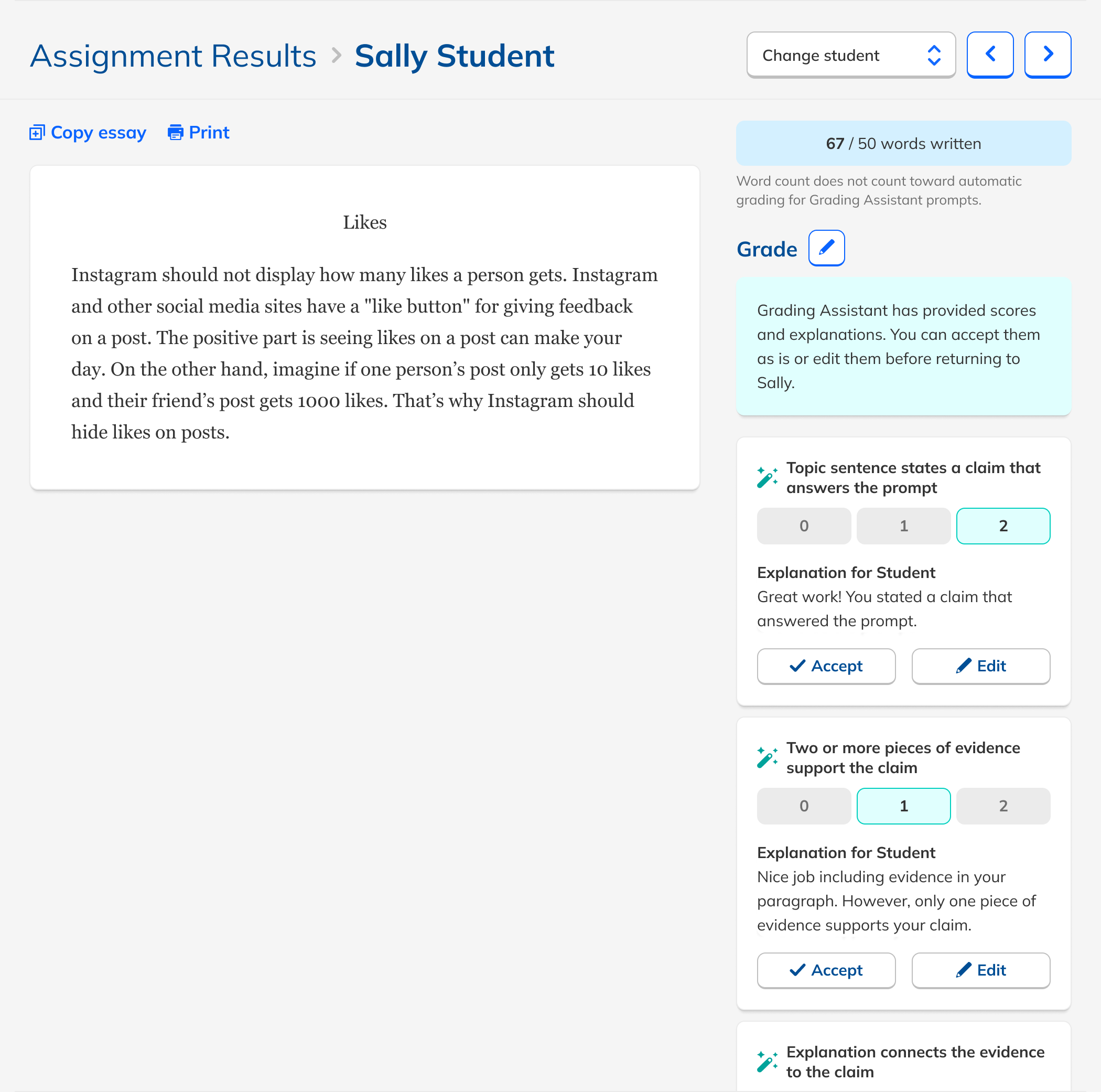
Teachers edited scores or feedback only 5% of the time, suggesting strong trust in the output. But they found individual approvals tedious.
Removed the approval step entirely
Grading became faster and simpler. AI feedback went live on save.
Added an autosave indicator
Without confirmation buttons, users weren't sure edits were saving. A quiet message resolved it.
Refined comment tone + structure
More positive, more specific, better personalized. Prompt engineering + feedback loops.
Added content safety flags
Rare cases where AI might paraphrase harmful student content, flagged for teacher review.
Making it feel native.
Moving from beta to full product meant weaving Grading Assistant into the platform rather than leaving it as a bolt-on feature.
Visual differentiation
Iconographic notation to distinguish GA assignments from standard ones throughout the teacher experience.
Free trial upsell
Free teachers could try Grading Assistant and decide whether to upgrade to Premium.
Enterprise benchmarks
District admins could choose and configure GA assignments at scale within the Benchmark feature.
Teachers who used Grading Assistant during the free trial were 70% more likely to upgrade to Premium.
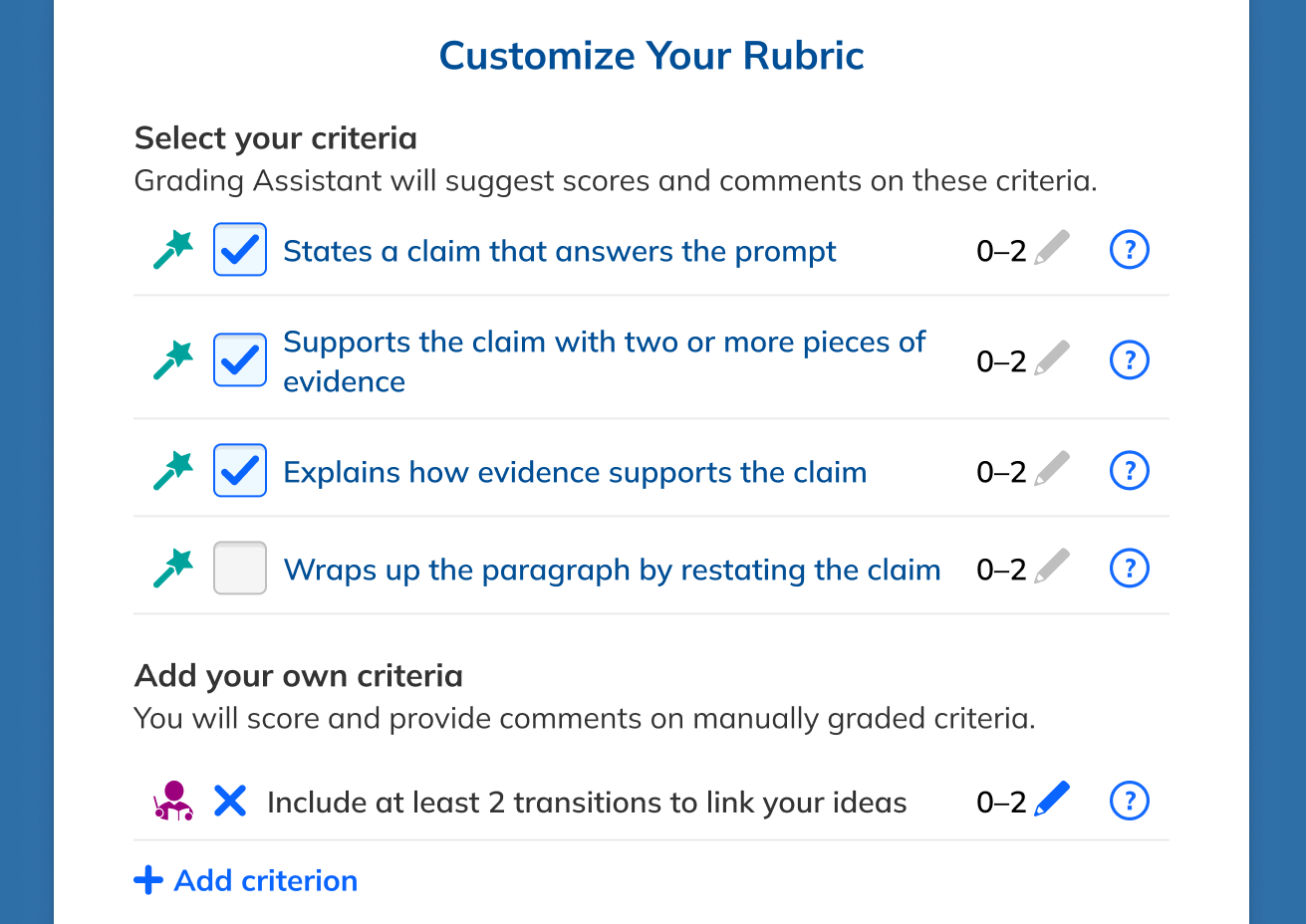
What we built.
reduction in grading time per assignment (82s → 37s)
more students received written feedback at all
more students received feedback within a single day
higher Premium upgrade rate from trial users
With the concept proven, the next phase focused on expanding coverage: longer essays, additional genres, and better usability on smaller screens.