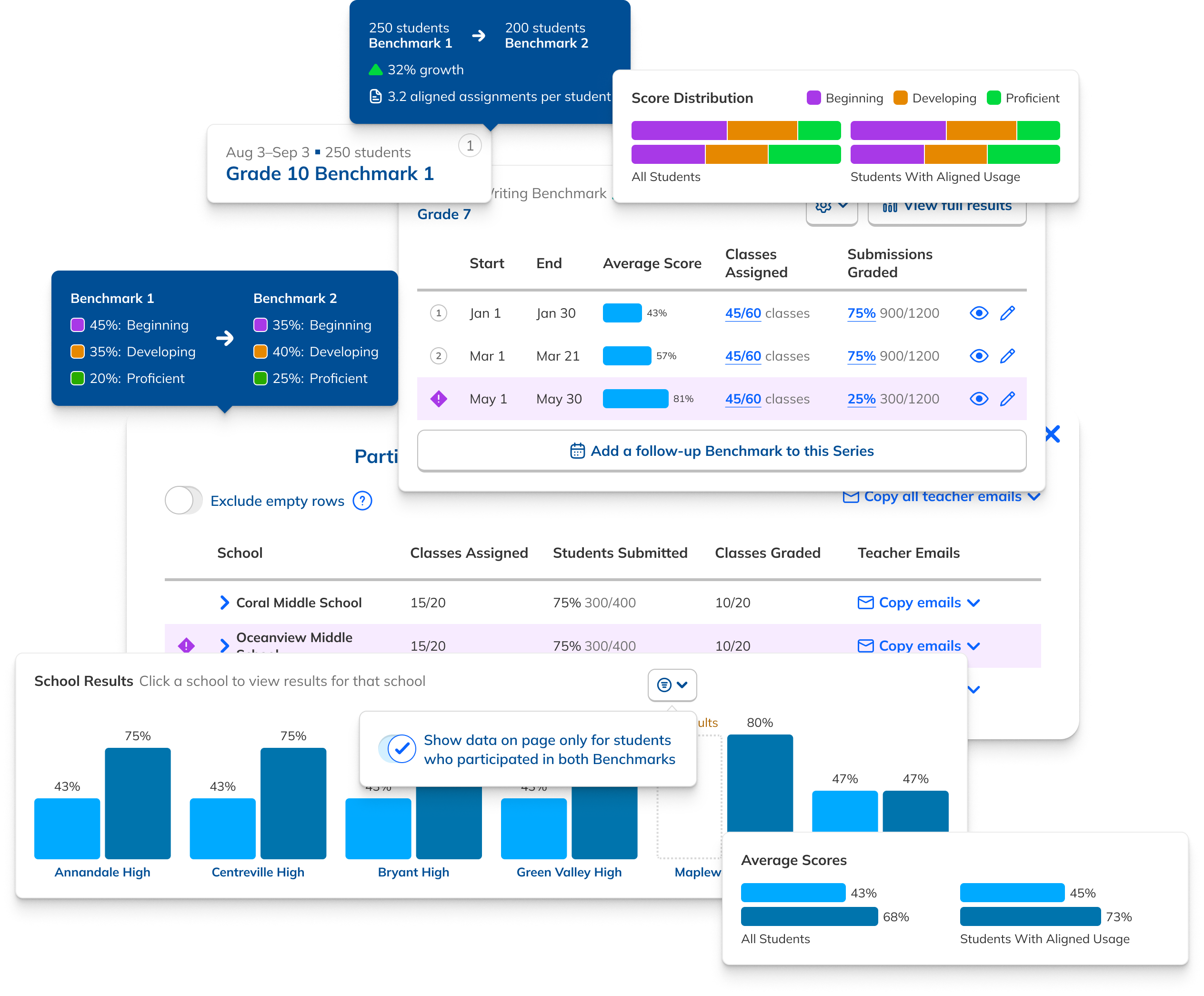
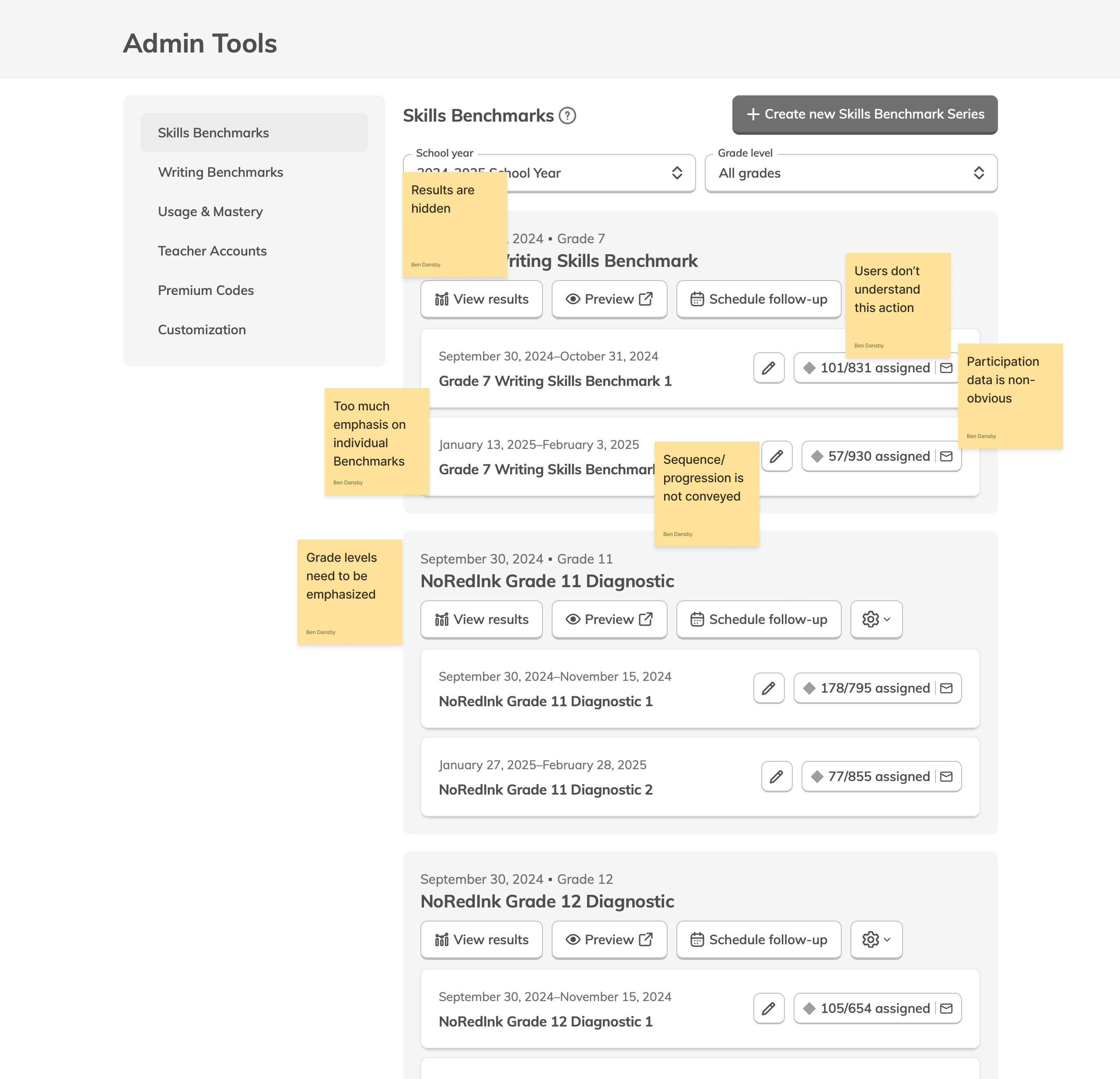
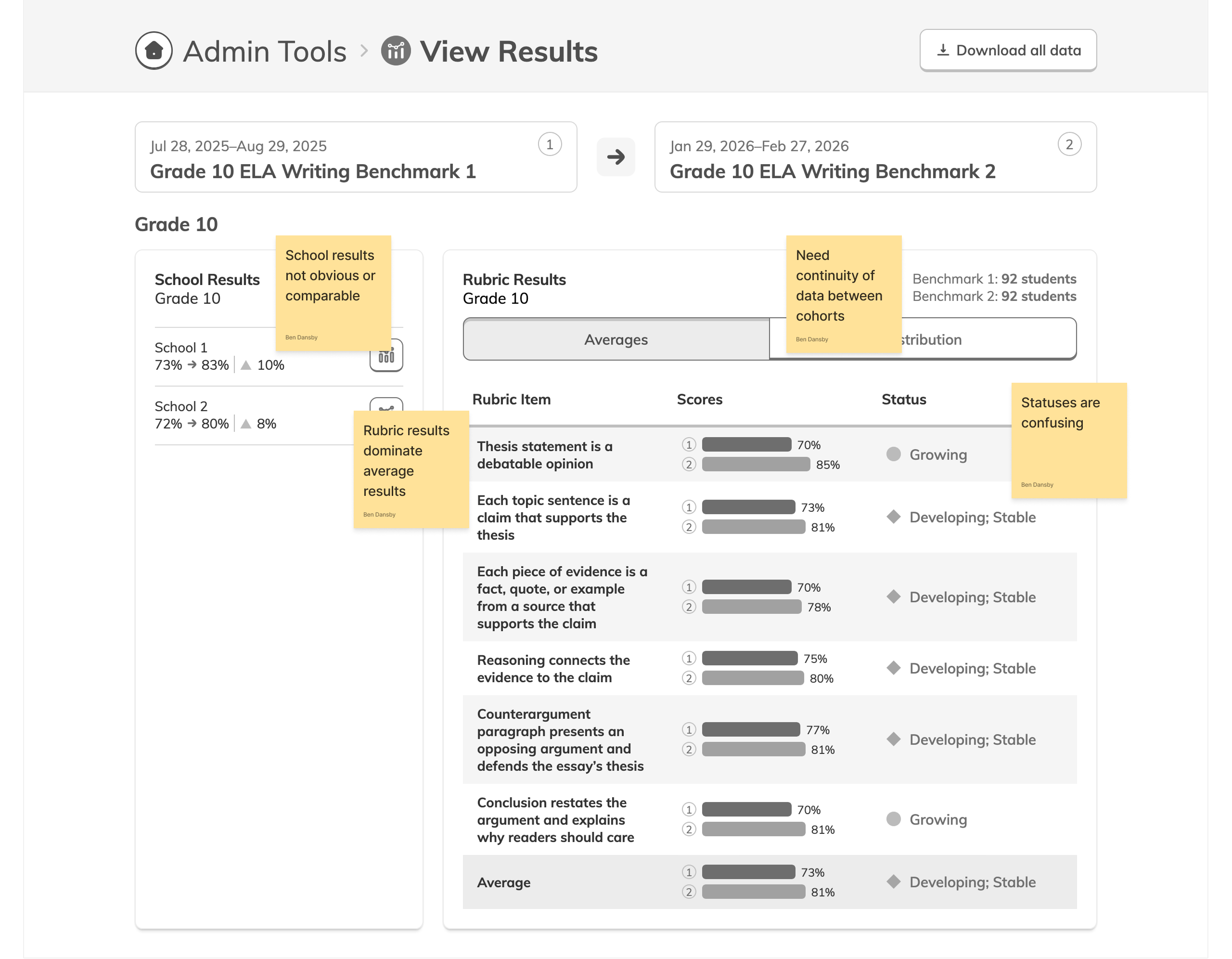
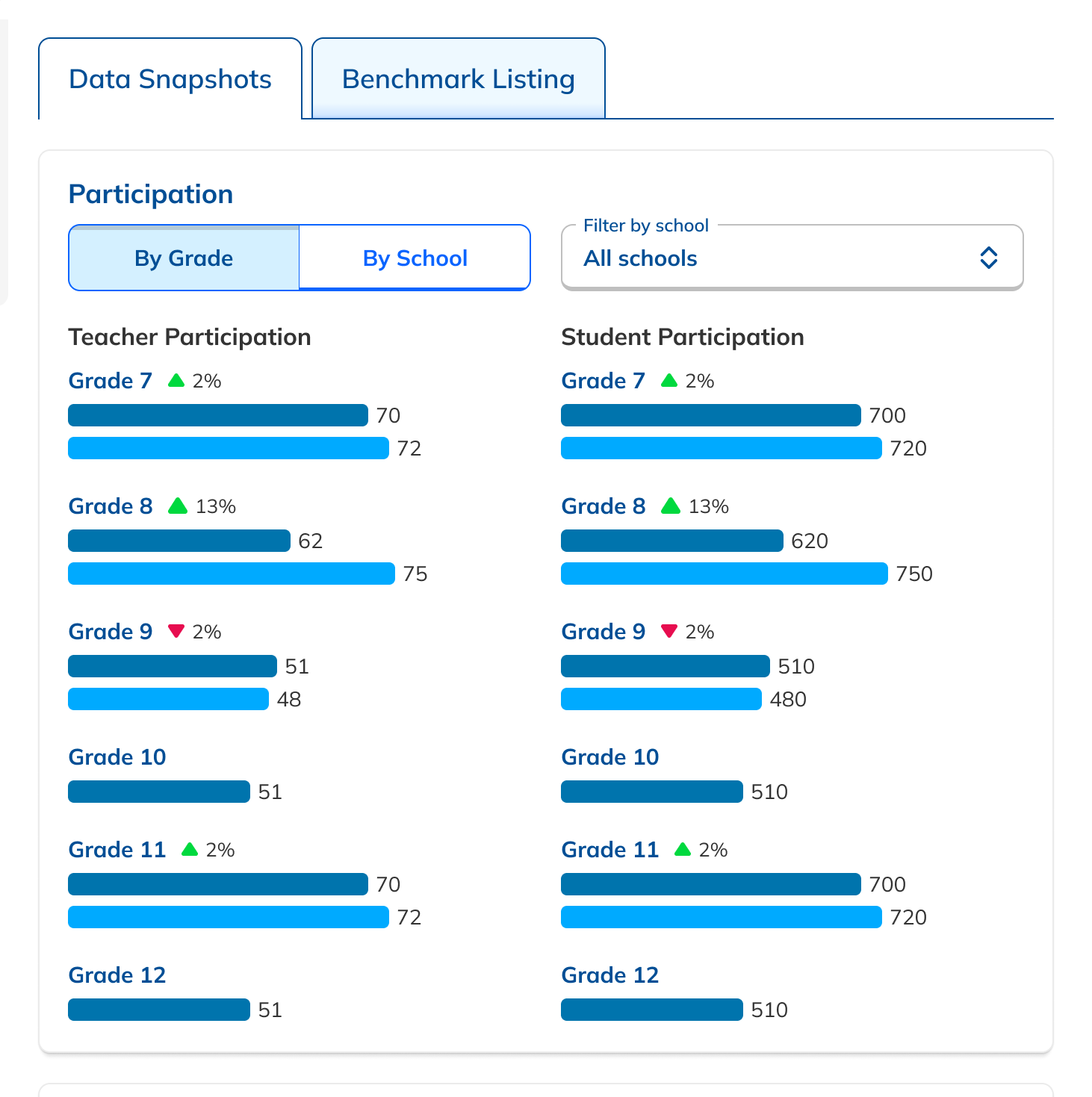
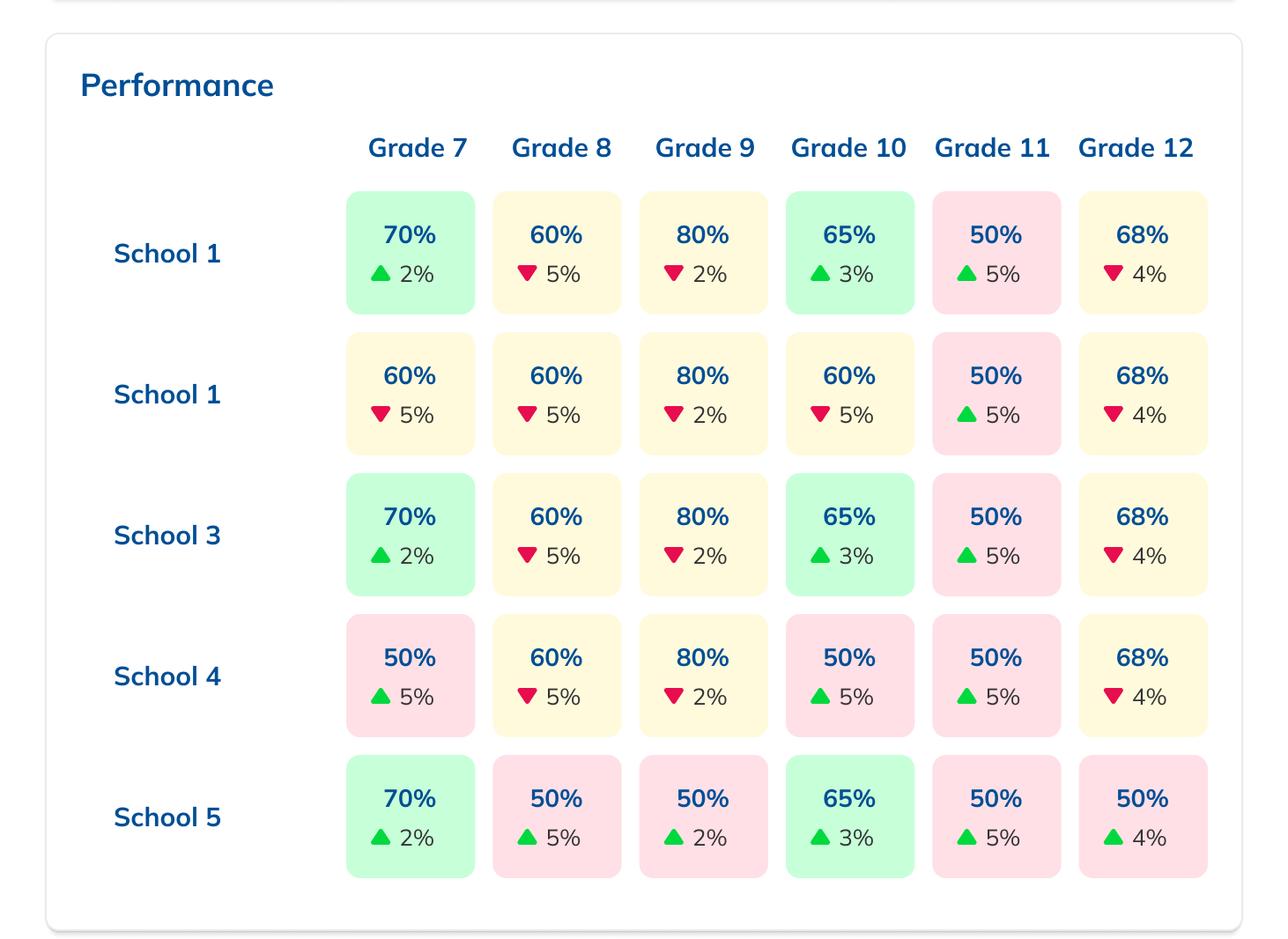
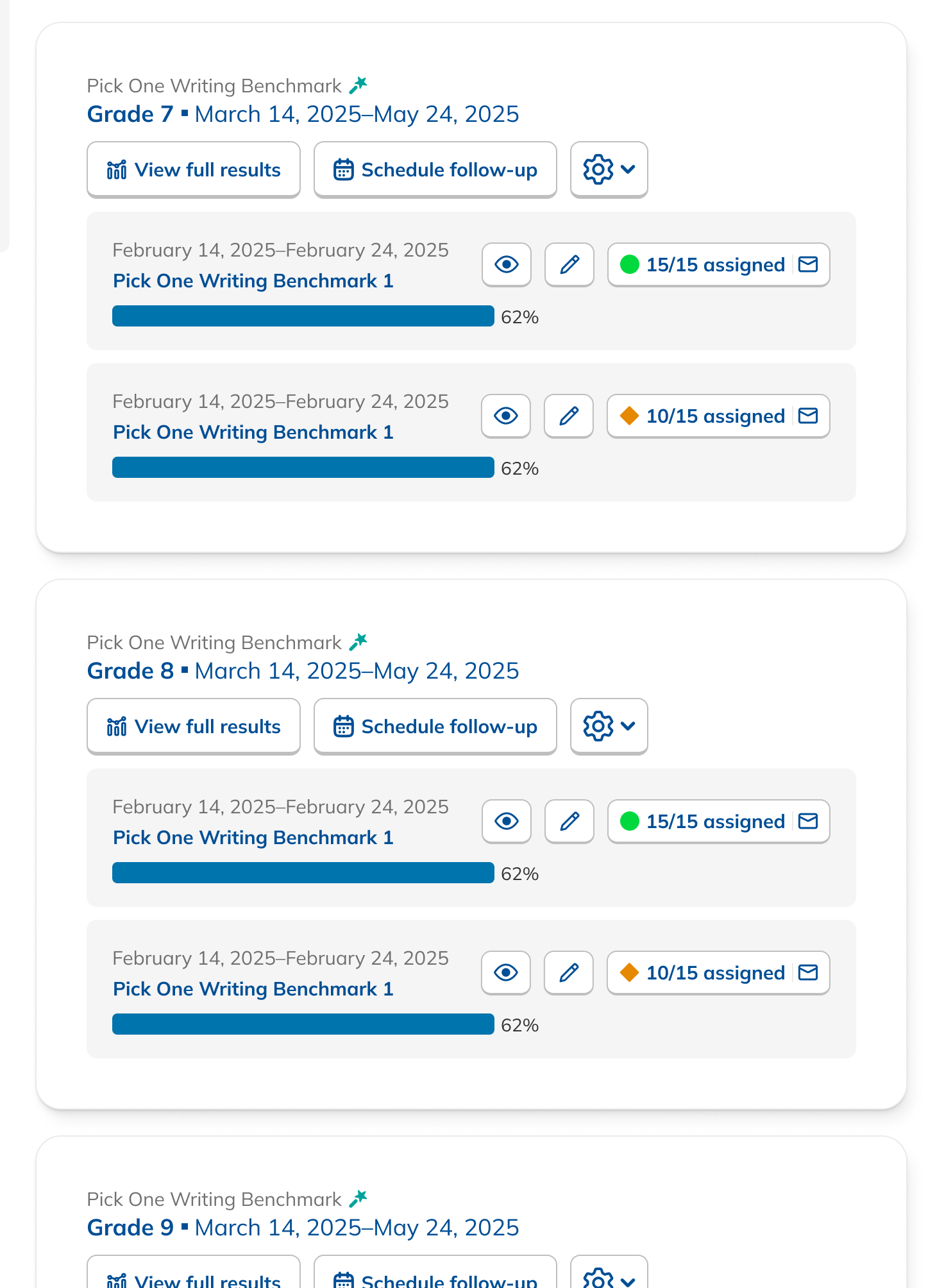
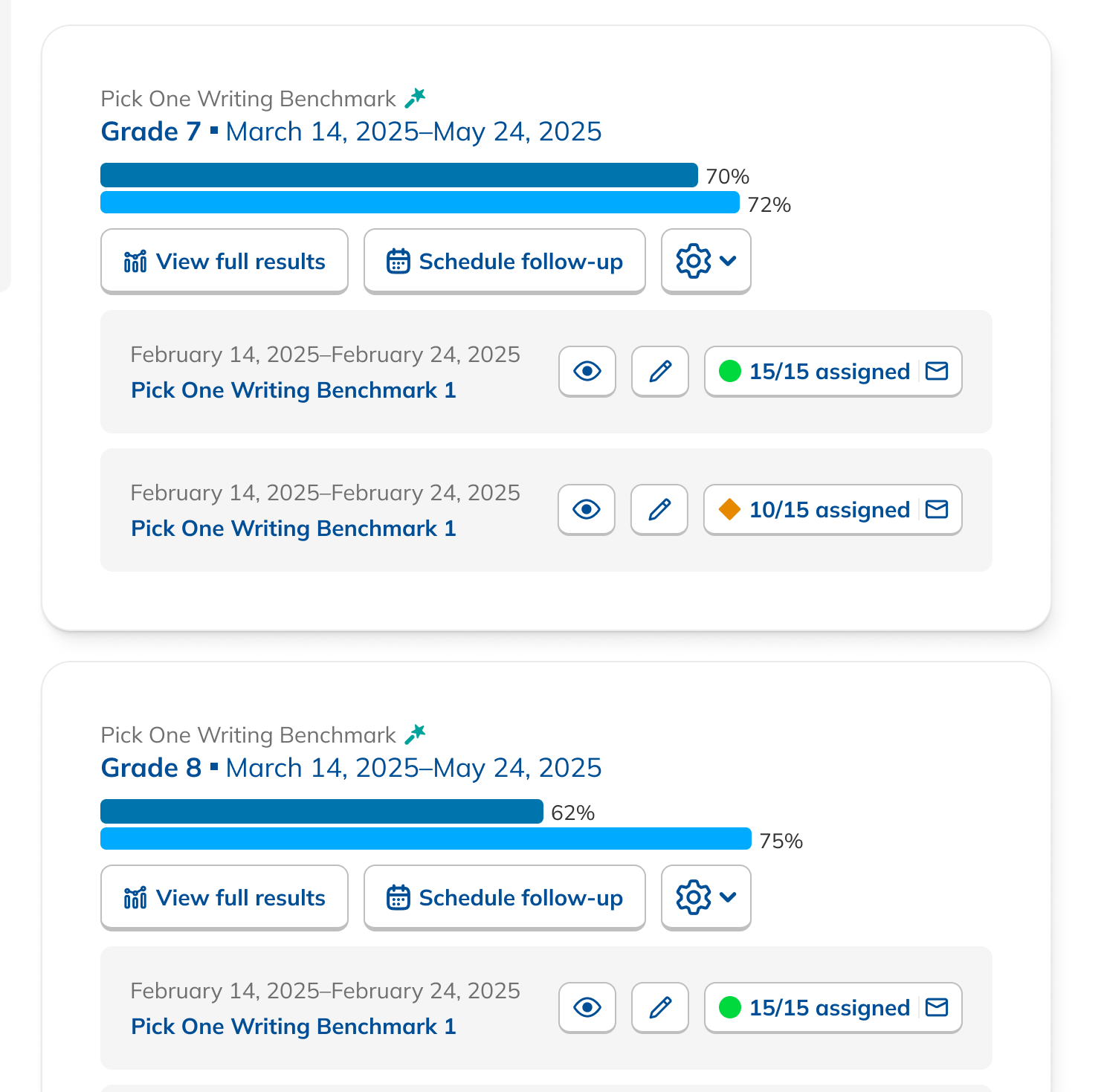
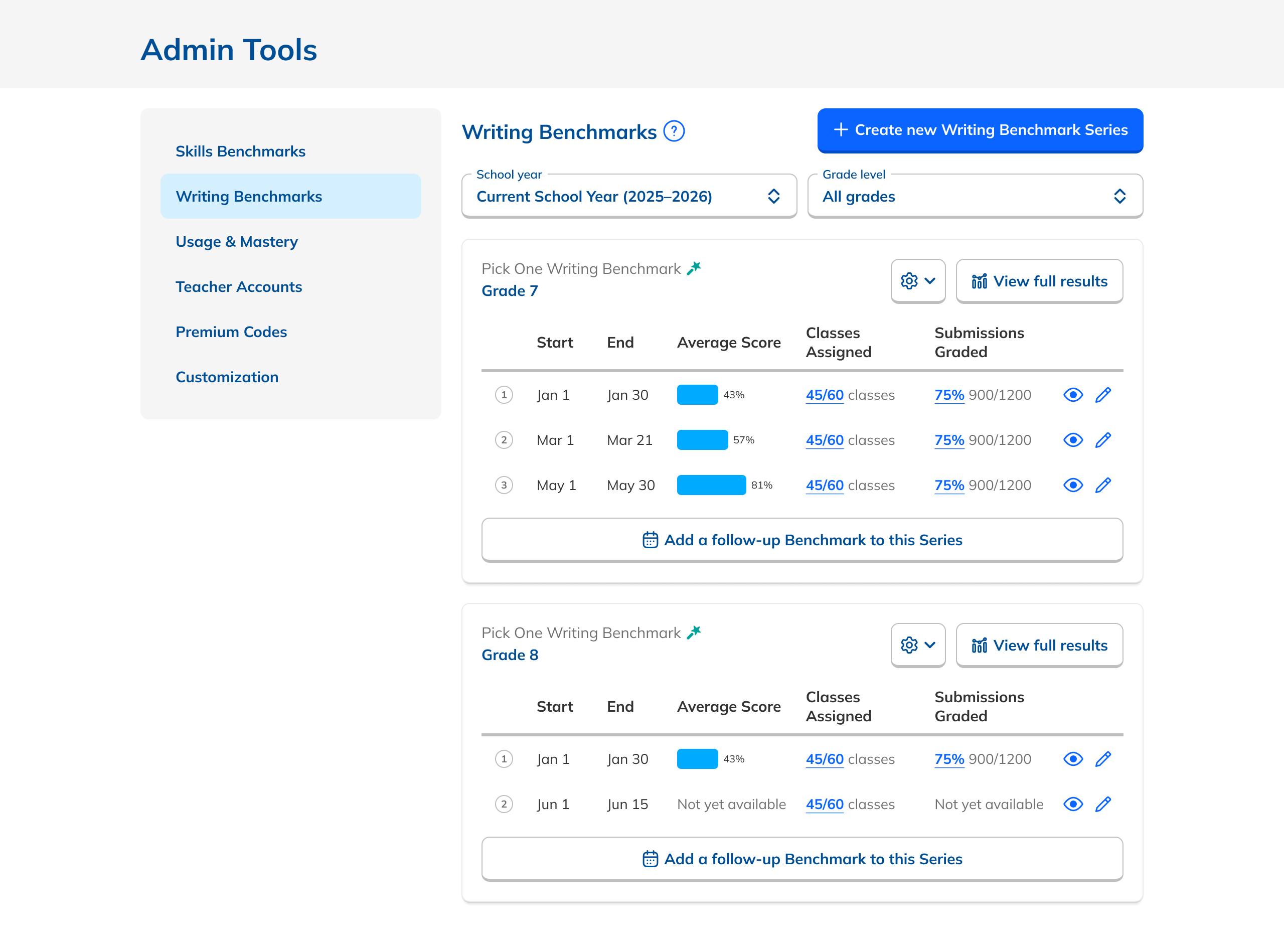
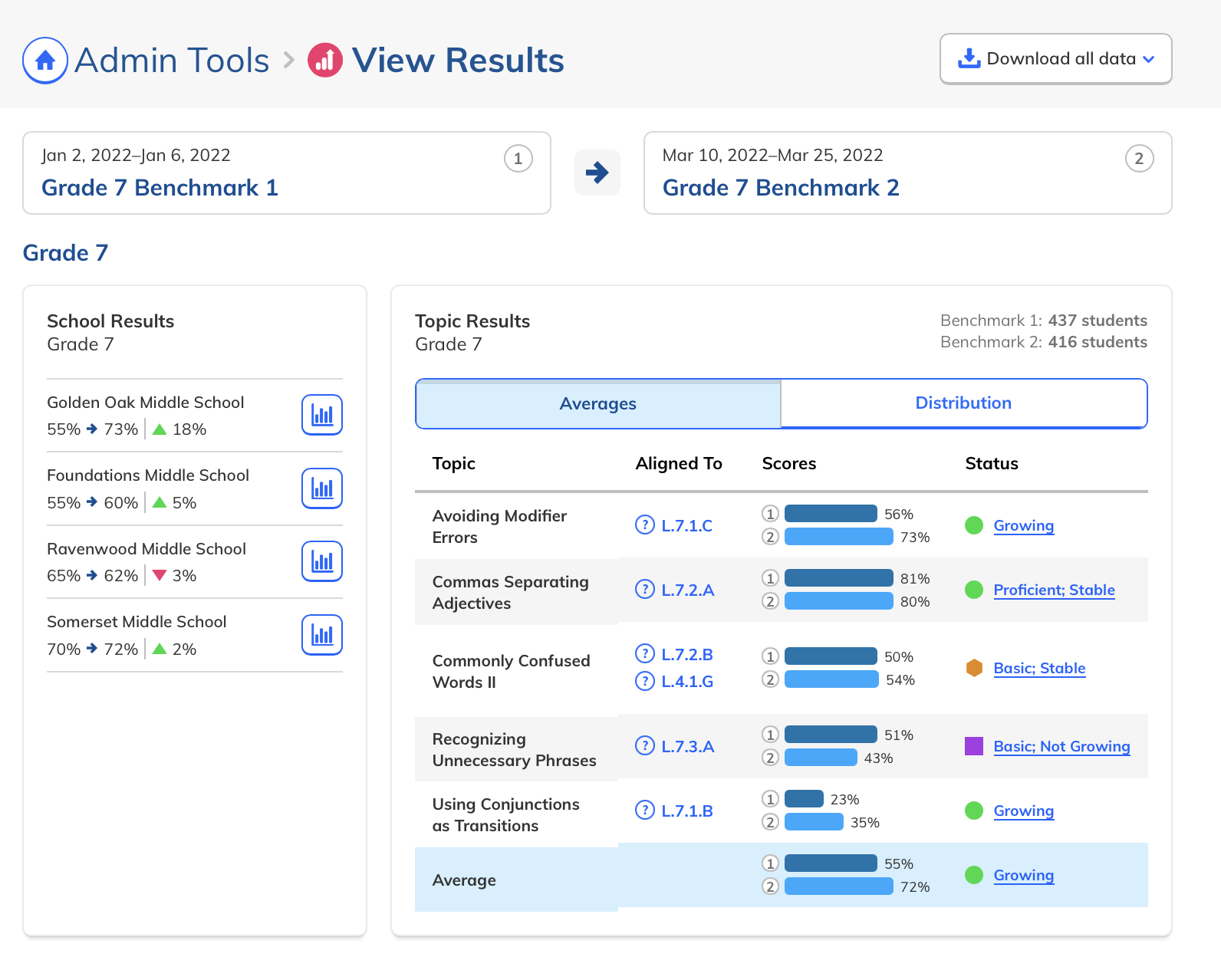
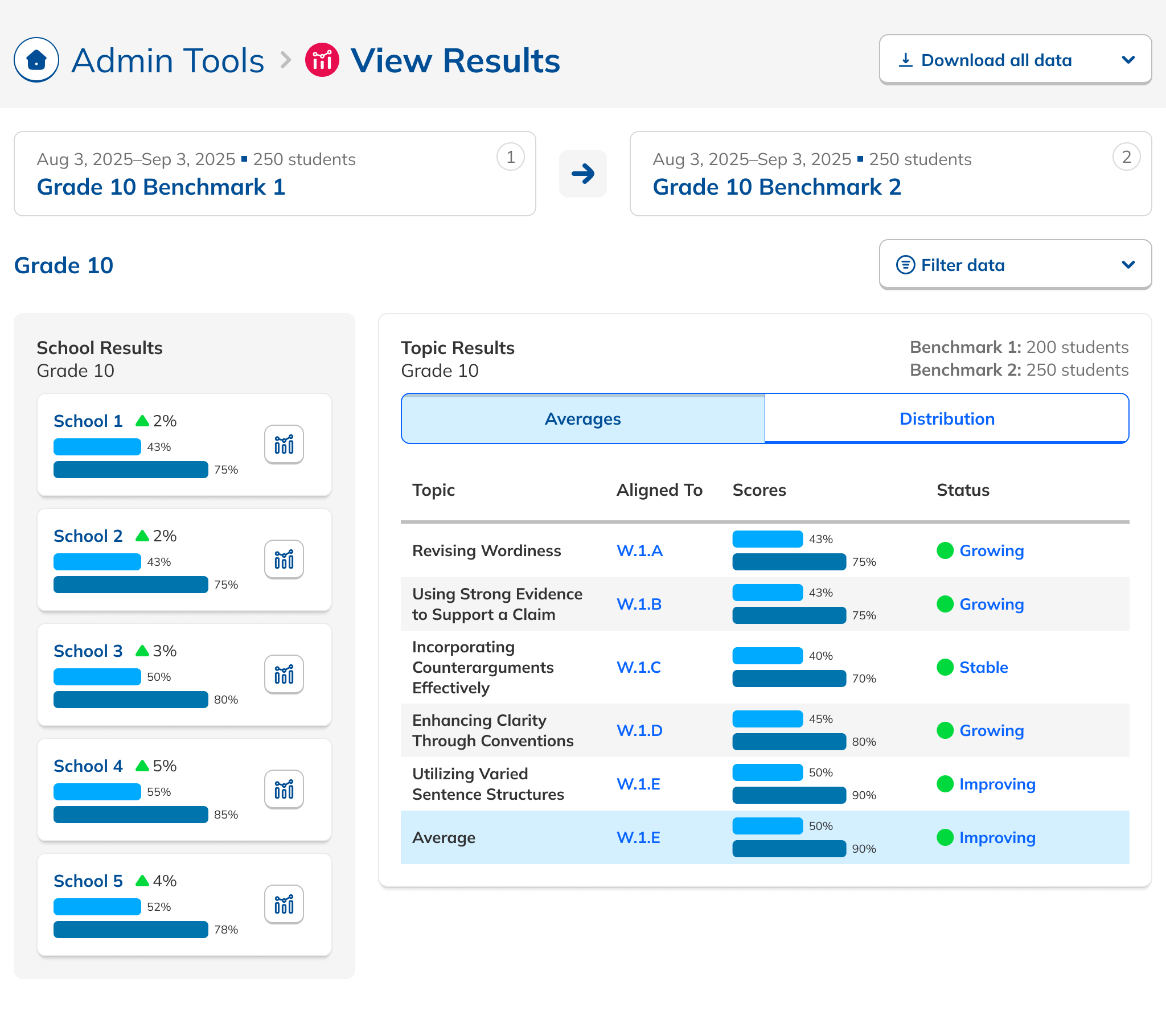
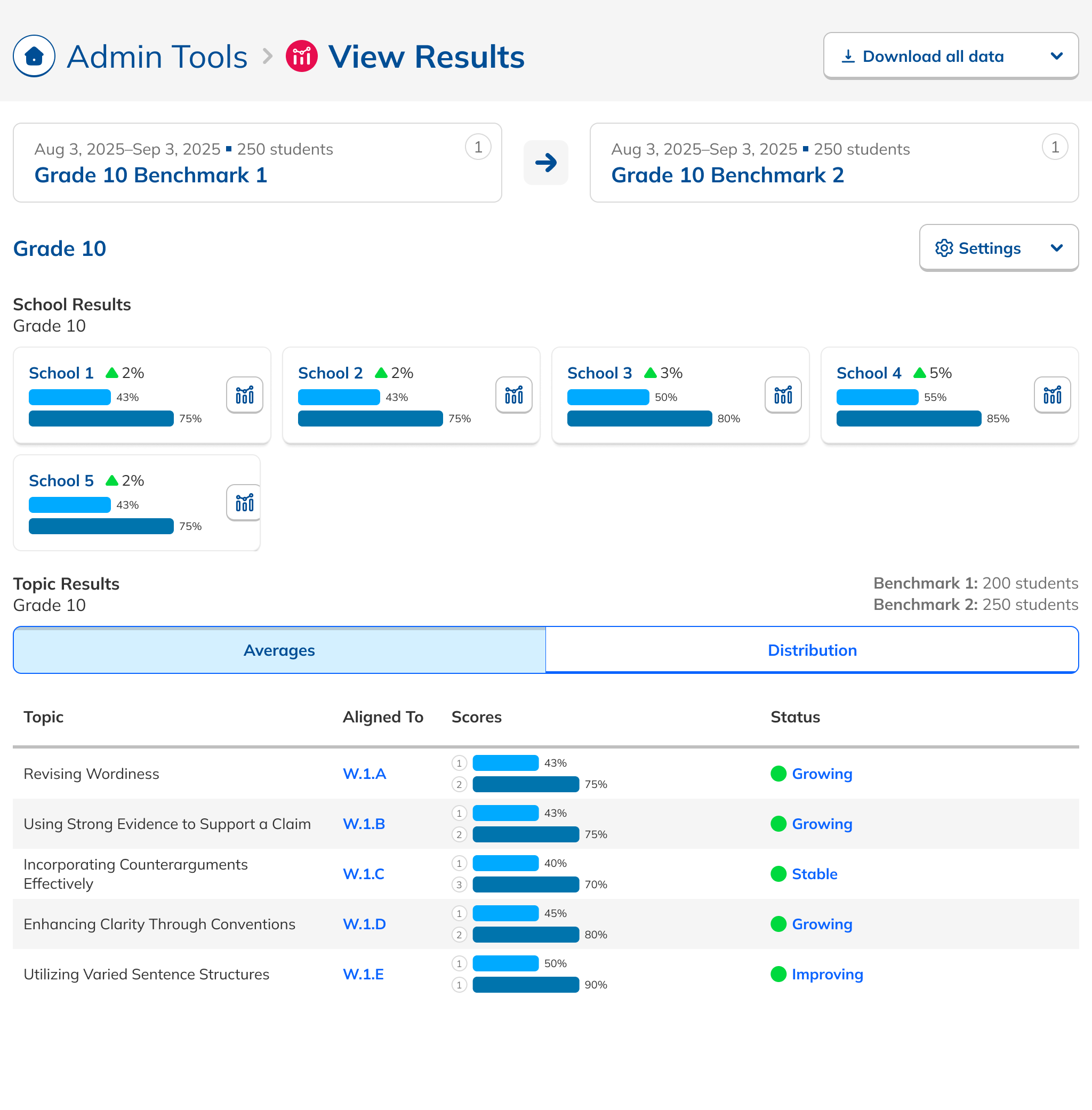
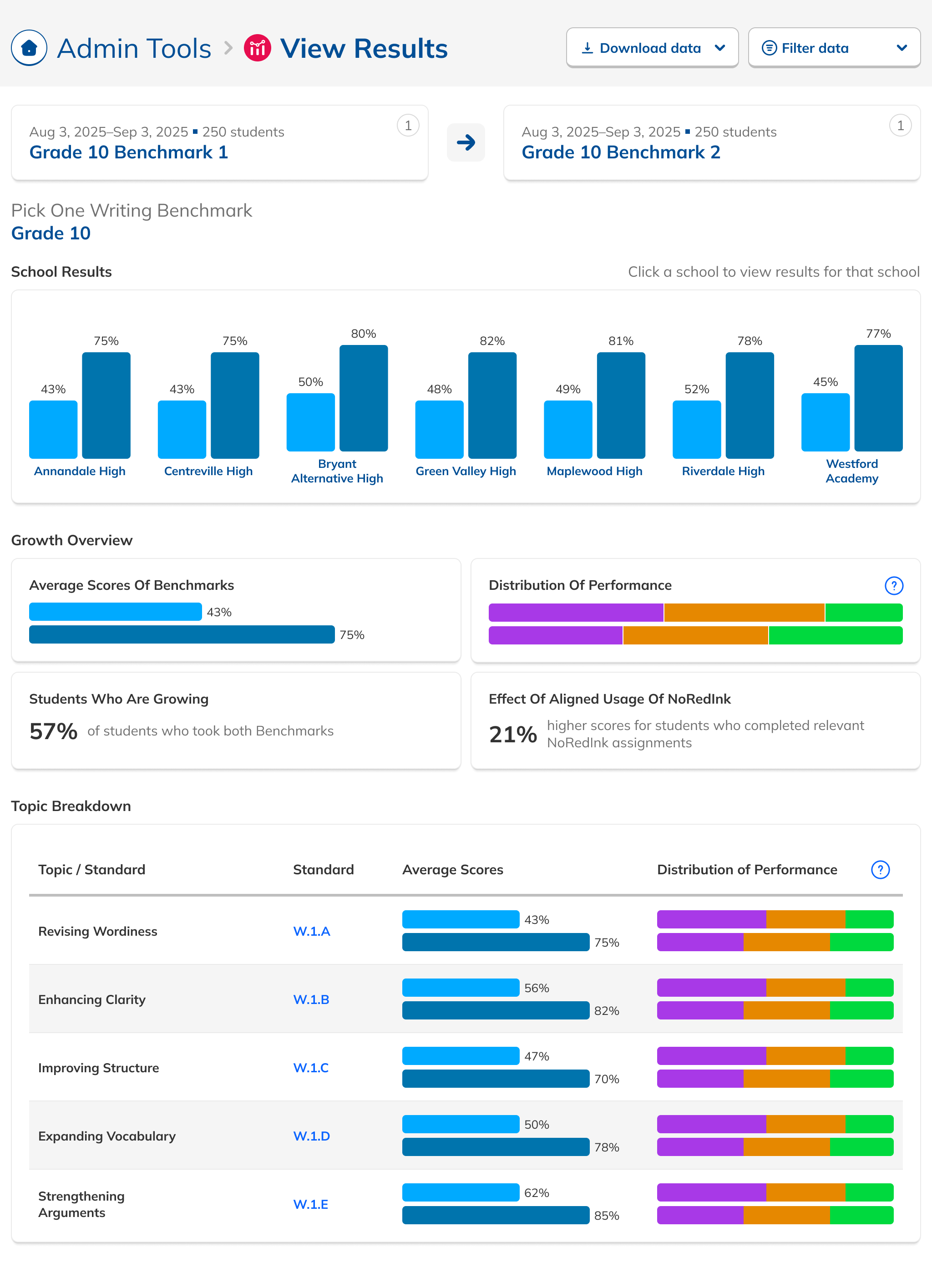
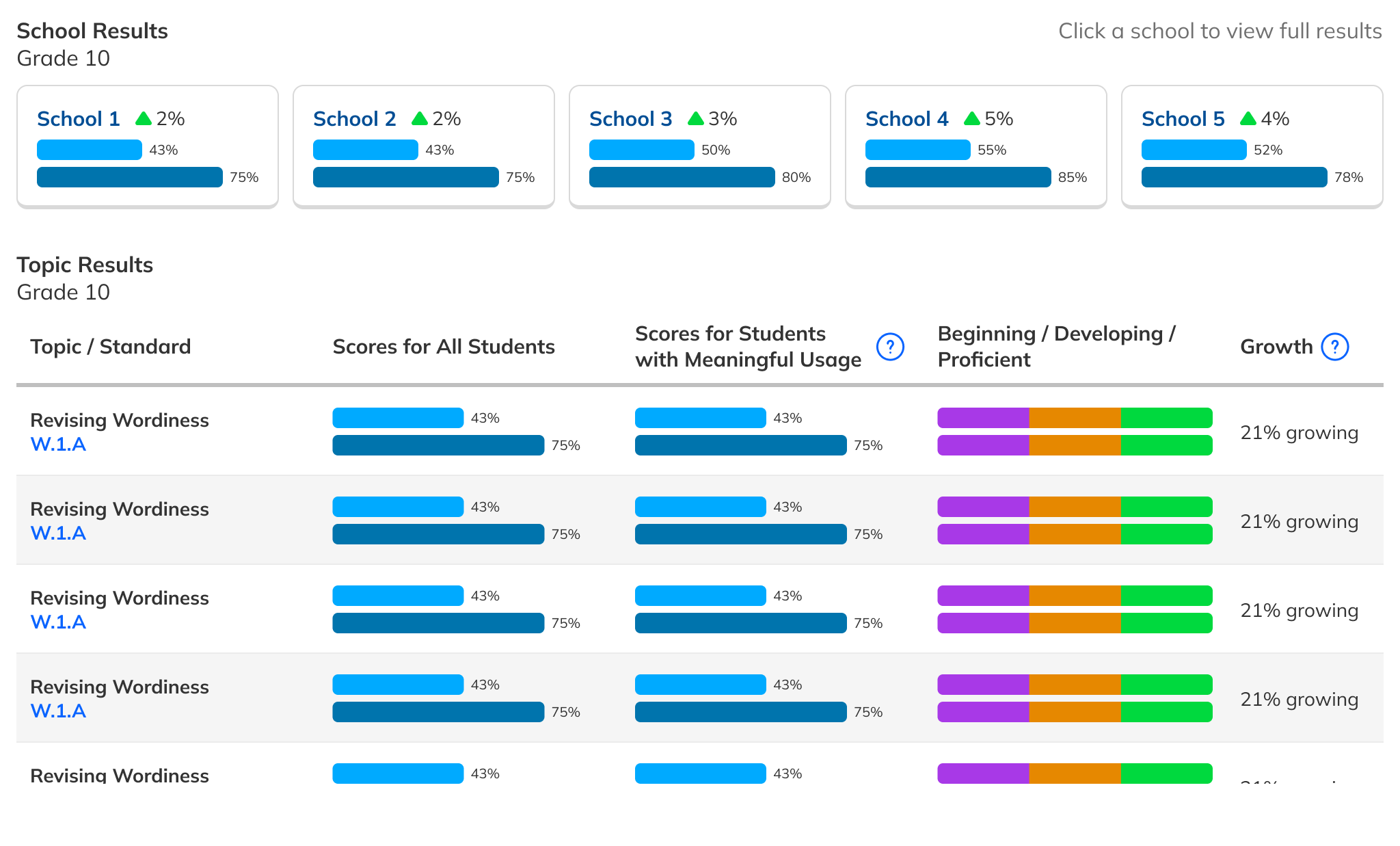
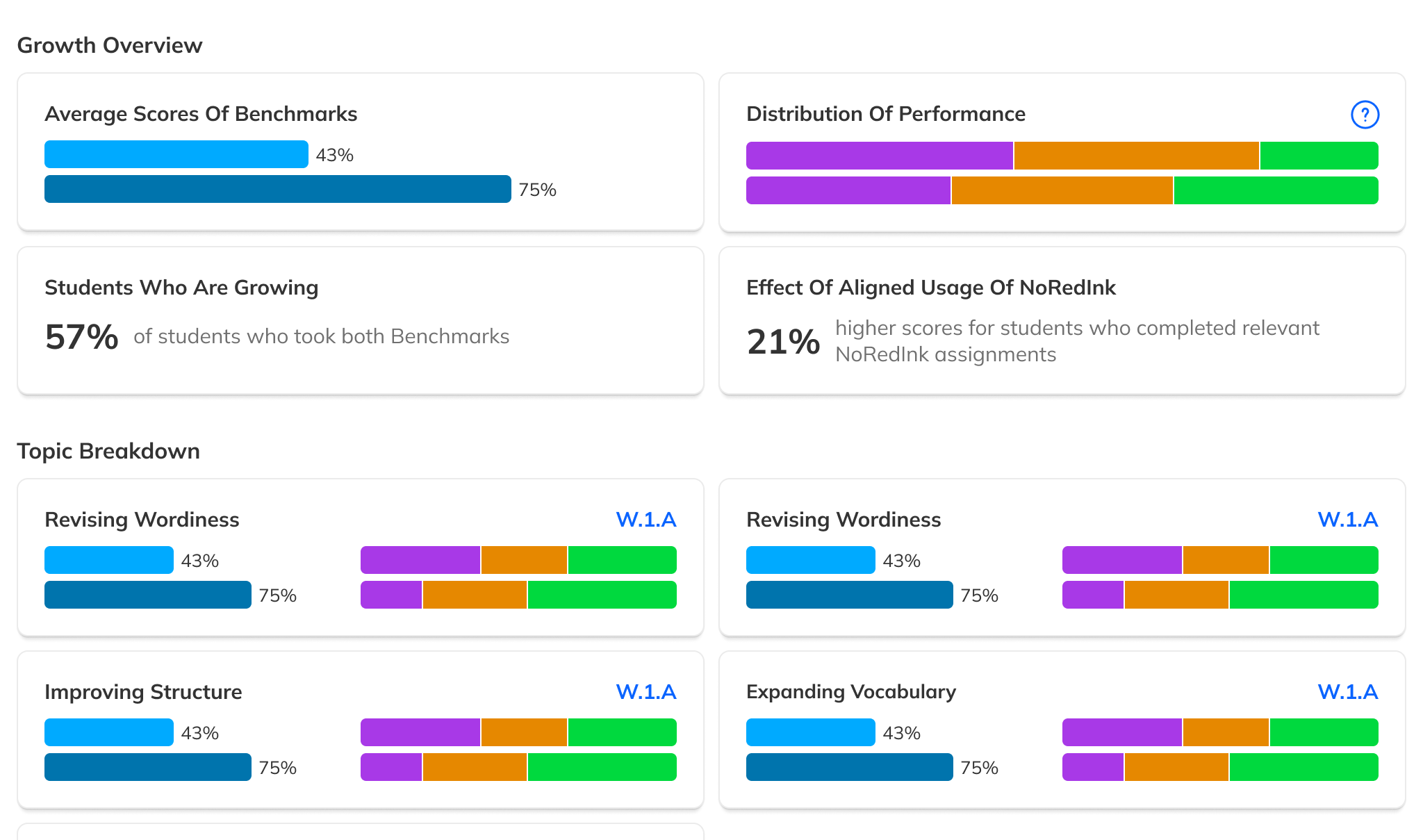
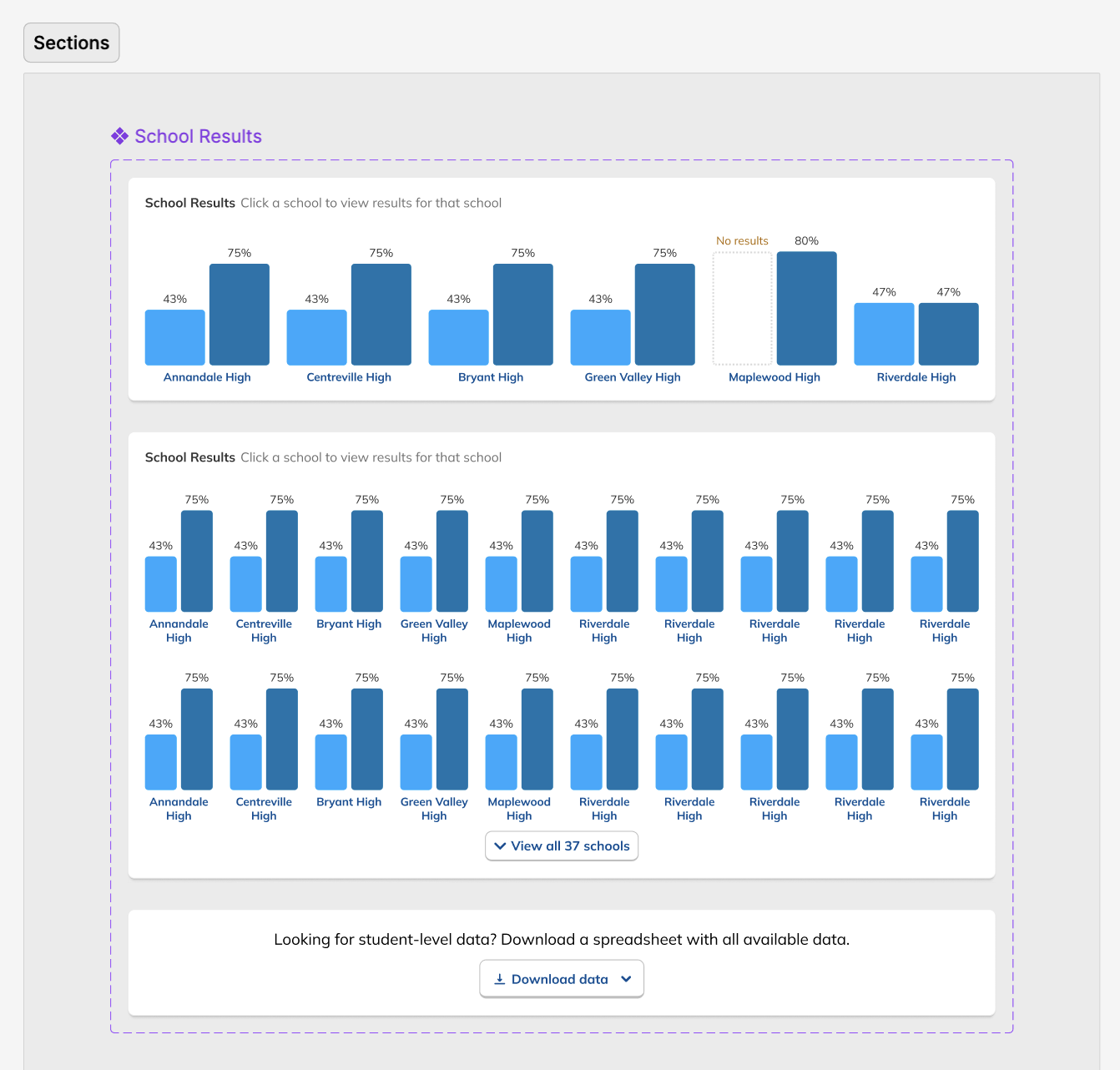
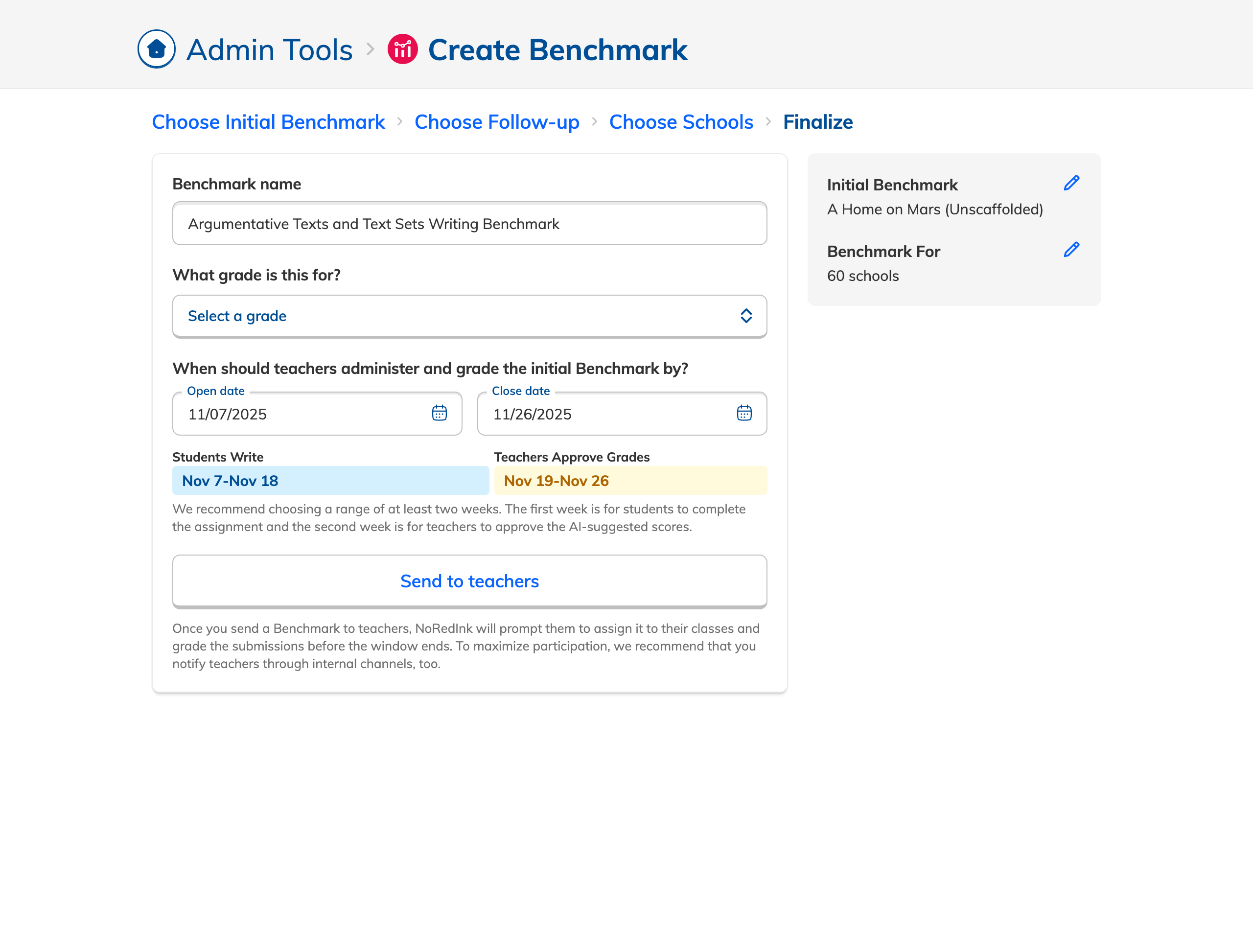
During our research phase, we heard from Customer Success that, though viewing results by individual score was important to customers, we were in fact putting too much emphasis on them at the expense of an overall score. In some cases, users didn't notice that overall scores were even available because they were subordinate to the skills. This was another case where the current design had the needed data, but was not presenting it in the most useful way. We were providing data but not telling a good story with it.
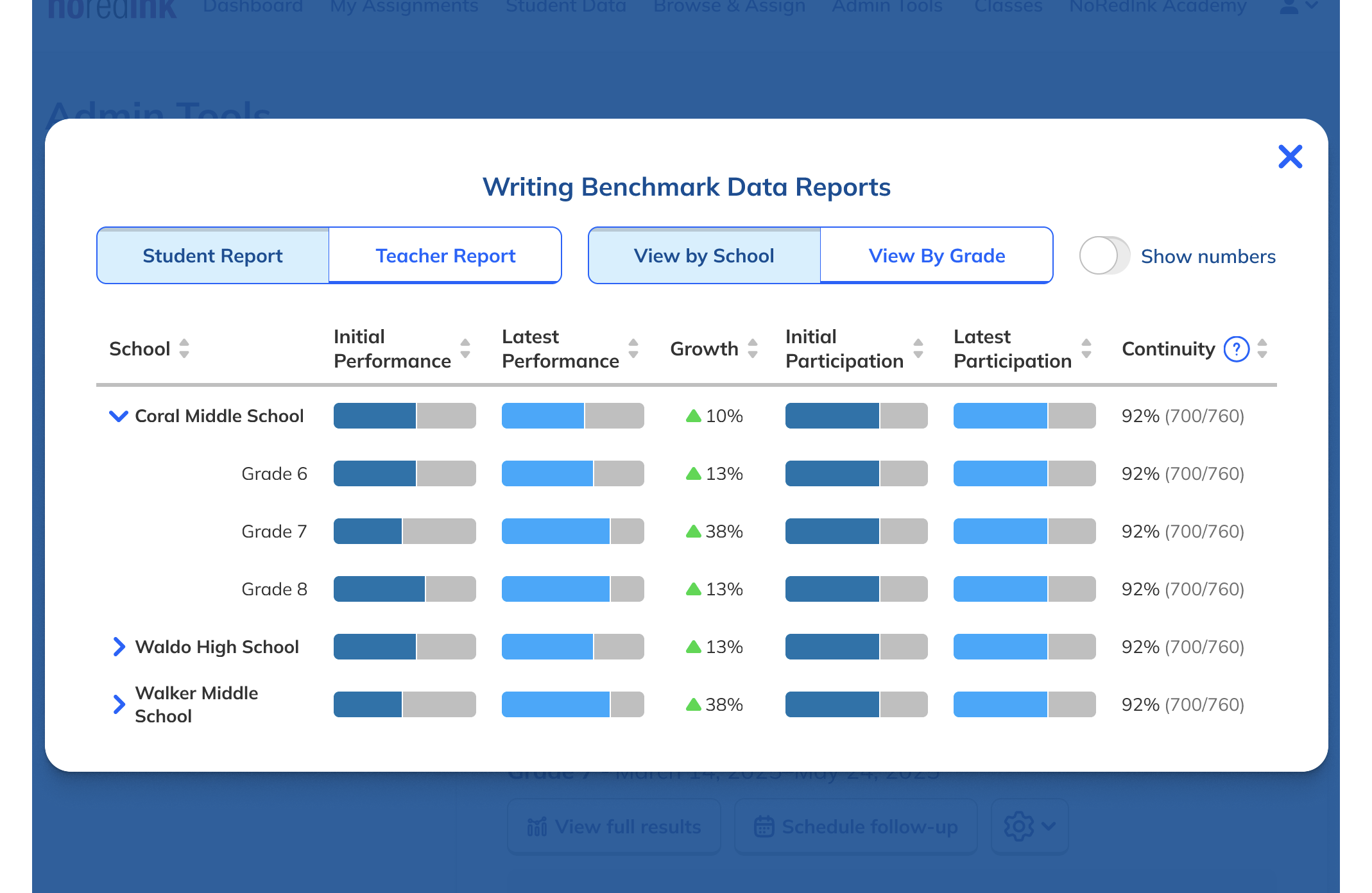
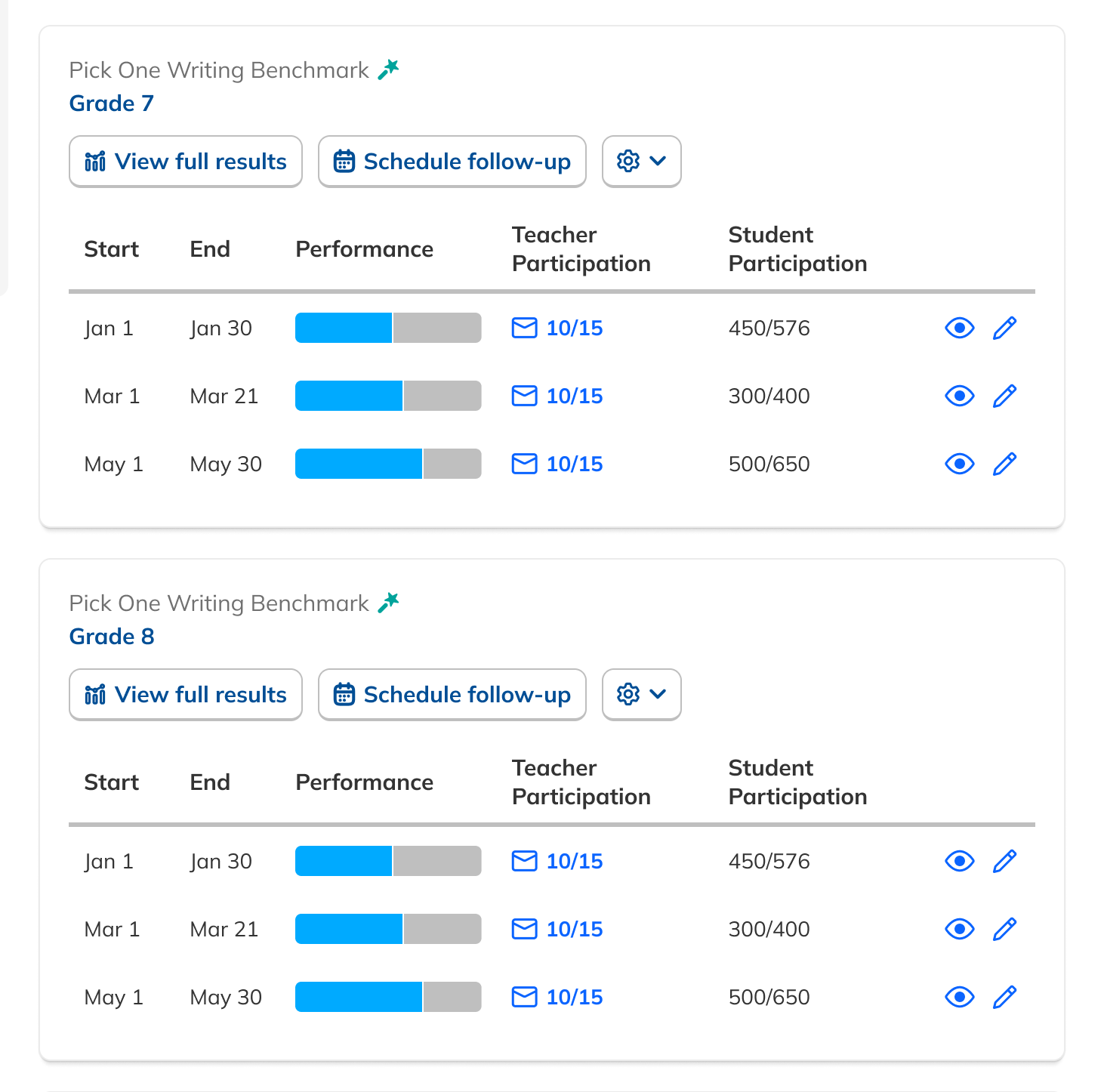
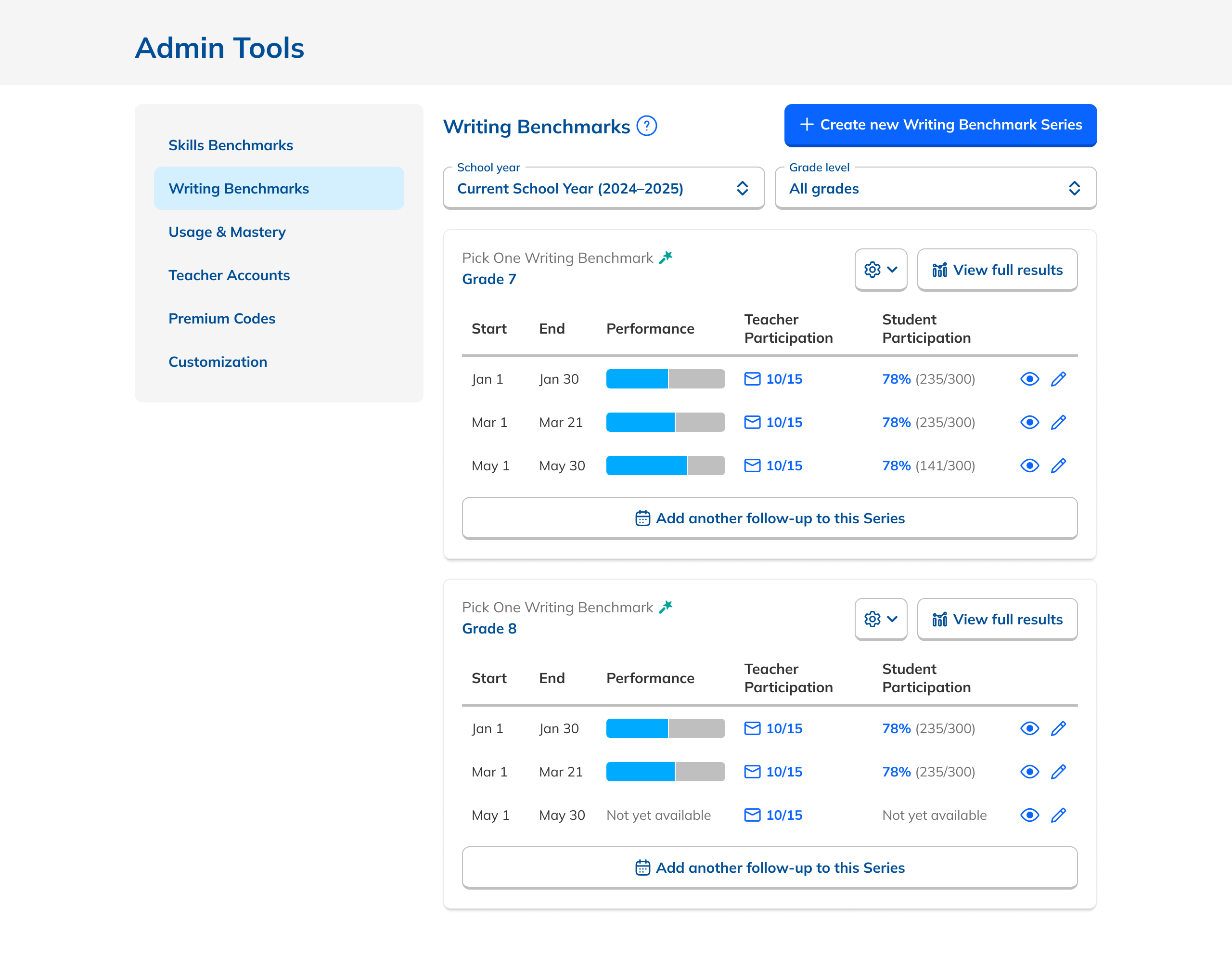
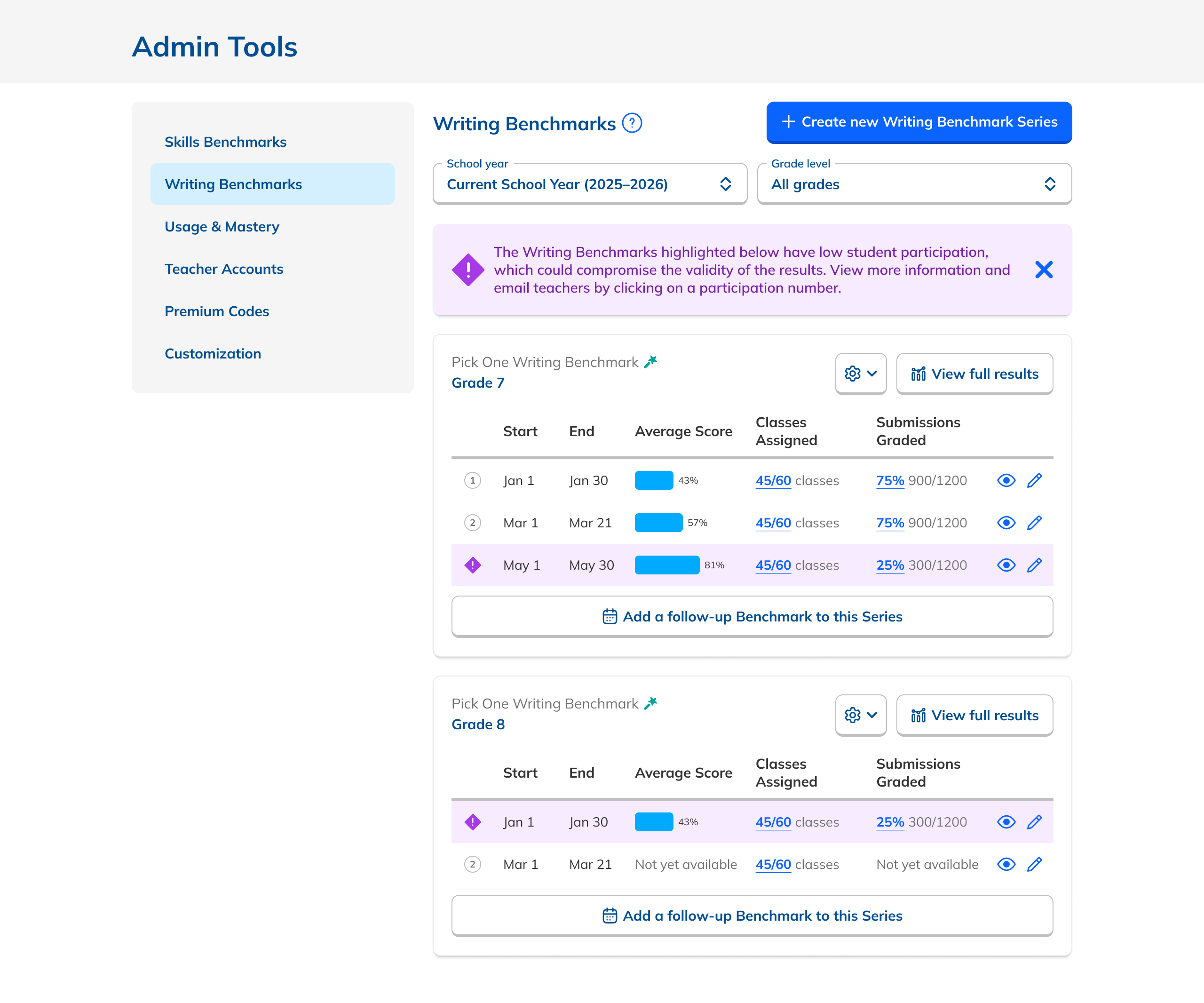
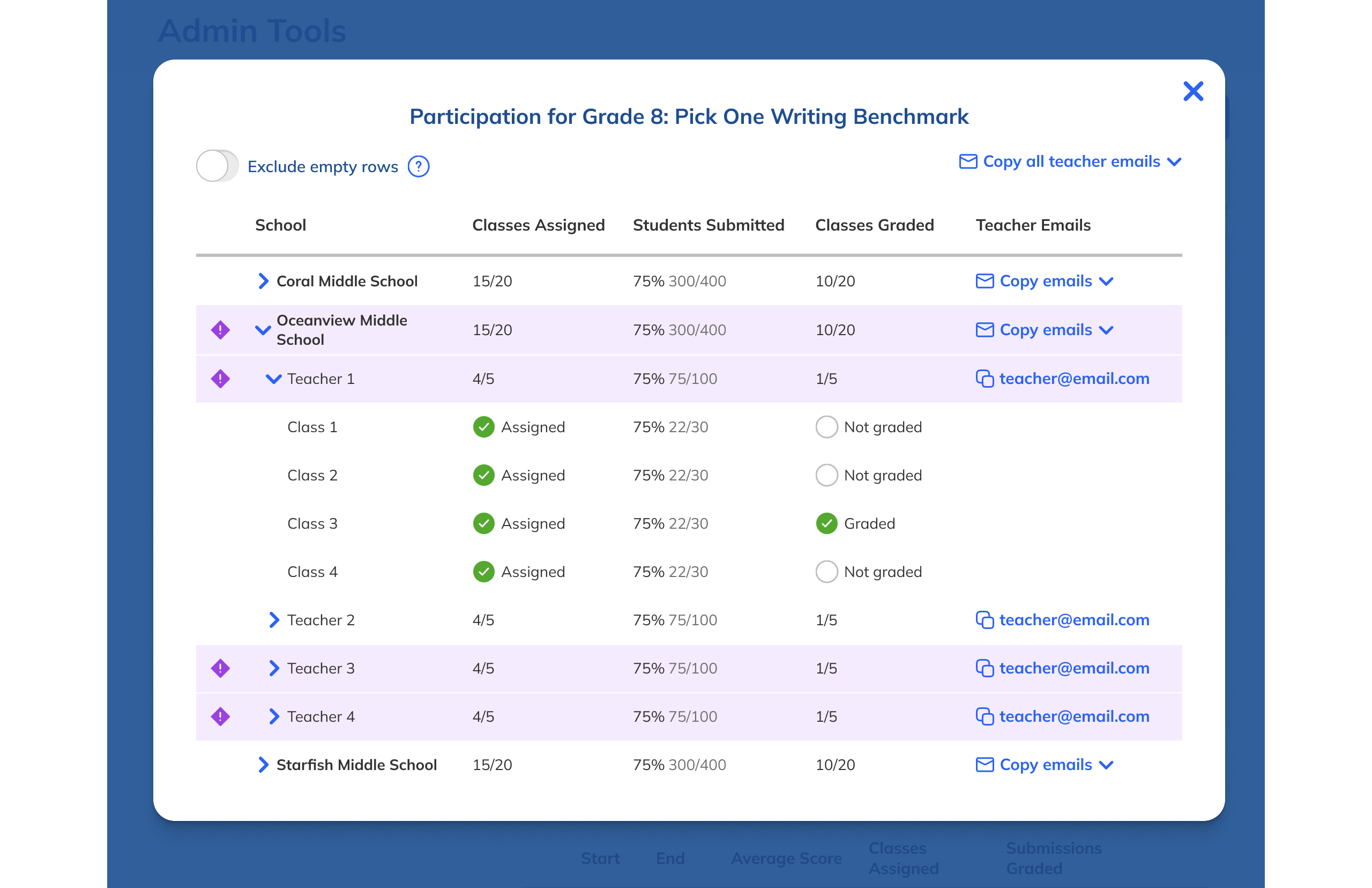
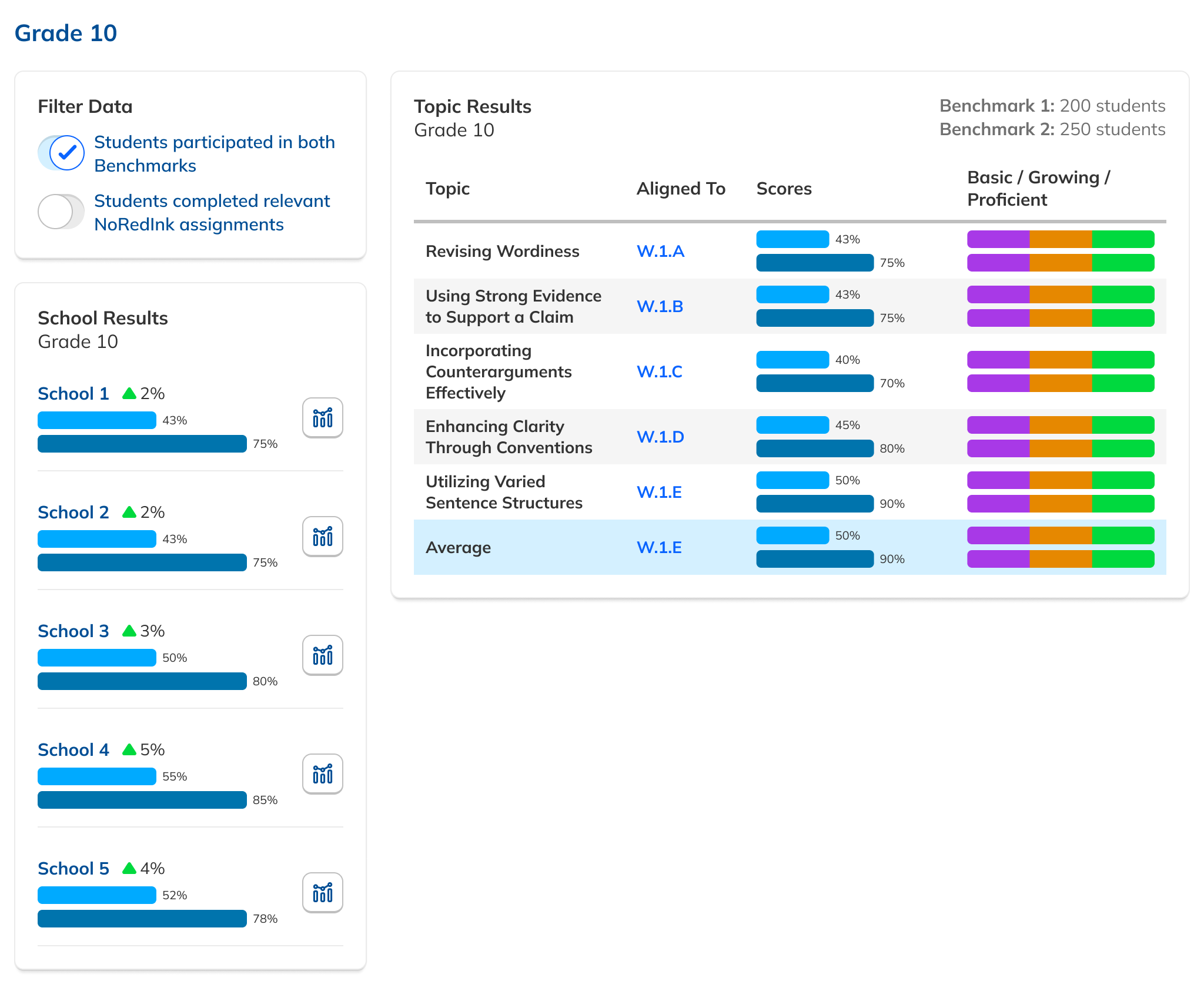
Our research had also revealed that, to ensure high fidelity results, admins needed to be able to view Benchmark data filtered to count only students who had taken both Benchmarks in a comparison view. This filtering need from customers coincided with one from NoRedInk itself. We wanted admins to be able to see data only from students who had completed activities on NoRedInk relevant to the skills assessed on the Benchmark. Having this view would allow us to demonstrate NoRedInk's efficacy to admins.
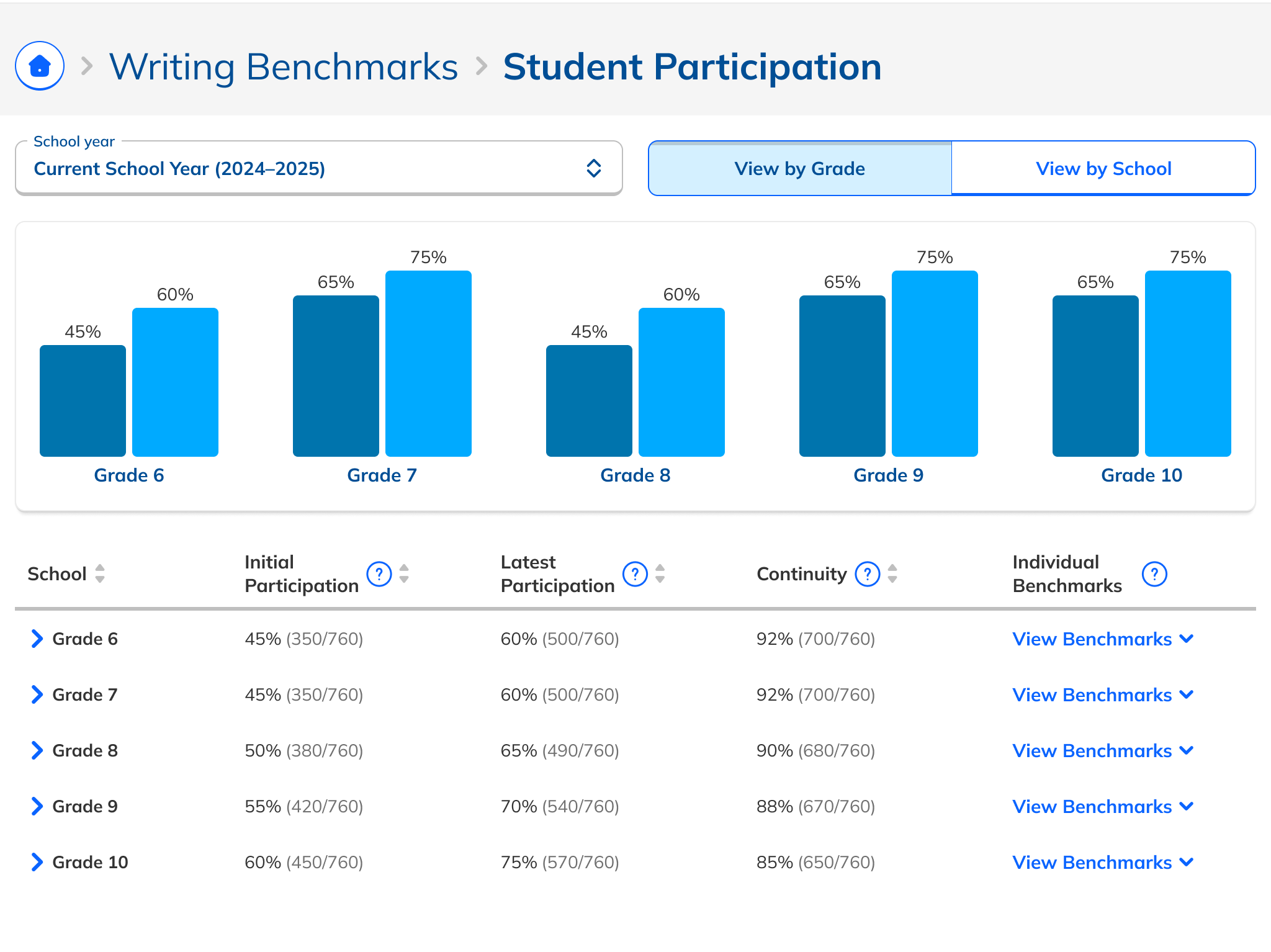
After some experimentation, I arrived at a design that offered more prominent overall performance data alongside the required filters. The filters were incorporated into headlining numbers that sat nicely beside the overall performance data we had broken out. All in all, this layout told a clearer story of the results, offered additional data, and provided control over the filtering of that data. We had arrived at a design that started to address the themes we heard during our research: clear, actionable data and useful trends.
During this design process, we started hearing from our leadership team that they weren’t sure whether or not the idea of showing efficacy data was actually to our benefit. This uncertainty persisted for the rest of the project, such that it ended up informing the design. The layout evolved to be more modular and I designed the page in a way that allowed the data and filter to be easily shown or hid based on future decisions or conditions.